รู้จ��ักกับ Statistical Learning
Statistical Learning คืออะไร ?
การเรียนรู้เชิงสถิติ (Statistical Learning) หมายถึงชุดของเครื่องมือที่ใช้ในการทำความเข้าใจกับชุดข้อมูลที่ซับซ้อน โดยเป็นสาขาที่กว้างขวางซึ่งมุ่งเน้นไปที่การสร้างโมเดลและการพยากรณ์ทั้งในแบบมีผู้สอน (Supervised Learning) และไม่มีผู้สอน (Unsupervised Learning)
ความสำคัญของการเรียนรู้เชิงสถิติและความเชื่อมโยงกับ Machine Learning
- เครื่องมือสำคัญ (Critical Toolkit): การเรียนรู้เชิงสถิติได้กลายเป็นเครื่องมือสำคัญสำหรับผู้ที่ต้องการทำความเข้าใจกับข้อมูล เนื่องจากงานจำนวนมากขึ้นเกี่ยวข้องกับข้อมูล ทักษะนี้จึงกลายเป็นสิ่งจำเป็นสำหรับทุกคน
- การประมาณค่า f (Estimating f): การเรียนรู้เชิงสถิติมีชุดวิธีกา�รสำหรับประมาณฟังก์ชัน f ซึ่งแสดงความสัมพันธ์ระหว่างตัวแปรผลลัพธ์ (Y) และตัวพยากรณ์ (X) หนึ่งตัวหรือมากกว่า การประมาณ f ช่วยให้สามารถทำได้ทั้งการพยากรณ์ (Prediction) และการอนุมาน (Inference)
- การเรียนรู้แบบมีผู้สอนและไม่มีผู้สอน: วิธีการเรียนรู้เชิงสถิติสามารถนำไปใช้ได้ทั้งในบริบทของ Supervised Learningและ Unsupervised Learning
- ใน Supervised Learning จะเป็นการสร้างโมเดลทางสถิติสำหรับพยากรณ์หรือประมาณค่าผลลัพธ์โดยใช้ตัวแปรนำเข้า
- ใน Unsupervised Learning จะเป็นการเรียนรู้ความสัมพันธ์และโครงสร้างของข้อมูลโดยไม่มีตัวแปรผลลัพธ์มาชี้นำ
- ความเชื่อมโยงกับ Machine Learning: การเรียนรู้เชิงสถิติได้พัฒนาเป็นสาขาย่อยของสถิติที่มุ่งเน้นไปที่การสร้างโมเดลและการพยากรณ์ทั้งในแบบมีผู้สอนและไม่มีผู้สอน
- นอกจากนี้ ตั้งแต่ช่วงปี 1990 เป็นต้นมา การเพิ่มขึ้นของพลังประมวลผลทำให้เกิดความสนใจอย่างมากจากผู้ที่ไม่ใช่นักสถิติ ซึ่งต้องการใช้เครื่องมือสถิติที่ล้ำสมัยในการวิเคราะห์ข้อมูลของตน
- ความก้าวหน้าของการเรียนรู้เชิงสถิติได้รับแรงผลักดันจากการมีซอฟต์แวร์ที่ทรงพลังและใช้งานง่ายมากขึ้น เช่น Python ซึ่งเป็นระบบที่ได้รับความนิยมและสามารถใช้งานได้ฟรี รวมถึงเทคนิคและแนวคิดของ Machine Learning ซึ่งแสดงให้เห็นถึงความเชื่อมโยงที่แข็งแกร่งระหว่างทั้งสองสาขาระหว่าง Statistic Learning และ Machine Learning
ทีนี้ เพื่ออธิบายให้ชัดเจน “แล้ว Statistic Learning กับ Machine Learning มีความแตกต่างกันอย่างไร”
- Statistical Learning เป็นชุดเครื่องมือที่ใช้ในการทำความเข้าใจกับข้อมูล โดยมุ่งเน้นทั้งการสร้างโมเดลแบบมีผู้สอน (Supervised Learning) และไม่มีผู้สอน (Unsupervised Learning) เพื่อทำการพยากรณ์หรือ��ประมาณค่าผลลัพธ์ตามตัวแปรนำเข้า หรือเพื่อเรียนรู้ความสัมพันธ์และโครงสร้างของข้อมูลโดยไม่มีตัวแปรผลลัพธ์ชี้นำ
- ในขณะที่ Machine Learning มักถูกใช้แทนกันกับ Statistical Learning แต่สามารถมองได้ว่า Machine Learning เป็นสาขาที่กว้างกว่า โดยรวมเอาเทคนิคจาก Statistical Learning ไว้ด้วย แต่ยังรวมถึงอัลกอริธึมและแนวทางจากวิทยาการคอมพิวเตอร์ ซึ่งให้ความสำคัญกับ การพยากรณ์และระบบอัตโนมัติ มากขึ้น
Statistical Learning เน้นไปที่ โมเดล, แนวคิด, ข้อสมมติ และการแลกเปลี่ยนข้อดีข้อเสียของแต่ละวิธี ซึ่งเป็นรากฐานสำคัญของหลายอัลกอริธึมใน Machine Learning (ที่เอาจริง ในปัจจุบันก็แทบจะถือว่าเป็นศาสตร์เดียวกันไปแล้ว)
Supervised vs Unsupervised
Supervised Learning และ Unsupervised Learning เป็นสองประเภทหลักของปัญหาใน Statistical Learning โดยความแตกต่างหลักอยู่ที่ว่ามีตัวแปรผลลัพธ์ (Response Variable) คอยกำกับกระบวนการเรียนรู้หรือไม่
Supervised Learning
ใน Supervised Learning ทุกการสังเกตของตัวแปรนำเข้า (xi) จะมีตัวแปรผลลัพธ์ที่เกี่ยวข้อง (yi) เป้าหมายคือการสร้างโมเดลที่อธิบายความสัมพันธ์ระหว่างตัวแปรผลลัพธ์และตัวแปรนำเข้า ซึ่งสามารถใช้เพื่อพยากรณ์ค่าผลลัพธ์ในอนาคต หรือทำความเข้าใจความสัมพันธ์ระหว่างตัวแปรได้ดียิ่งขึ้น
- ตัวอย่างของวิธีการใน Supervised Learning:
- Linear Regression
- Logistic Regression
ตัวอย่างปัญหาที่ใช้ Supervised Learning ได้
- ปัญหาการถดถอย (Regression Problem): ทำนายรายได้ของบุคคลโดยพิจารณาจากจำนวนปีของการศึกษาและอายุงาน ตัวแ�ปรผลลัพธ์คือ รายได้ (Income - ตัวแปรเชิงปริมาณ) และตัวแปรพยากรณ์คือลำดับปีของการศึกษาและอายุงาน เป้าหมายอาจเป็นการพยากรณ์หรือการทำอนุมาน
- ปัญหาการจัดหมวดหมู่ (Classification Problem): คาดการณ์ว่าผู้ป่วยจะ รอดชีวิตหรือเสียชีวิต โดยใช้ตัวแปรพยากรณ์ เช่น อายุ ความดันโลหิต และข้อมูลสุขภาพอื่นๆ ตัวแปรผลลัพธ์คือ สถานะการรอดชีวิต (ตัวแปรเชิงคุณภาพ) เป้าหมายอาจเป็นการพยากรณ์หรือการทำอนุมาน
- การพยากรณ์ราคาหุ้น: พัฒนาอัลกอริธึมเพื่อทำนายราคาหุ้นในอนาคตโดยอิงจากข้อมูลในอดีต
- การวินิจฉัยทางการแพทย์: คาดการณ์ว่าผู้ป่วยเคยมีภาวะ โรคหลอดเลือดสมอง (Stroke) หรือโรคลมชัก (Epileptic Seizure) หรือไม่ โดยพิจารณาจากผลการทดสอบทางการแพทย์
Unsupervised Learning
ใน Unsupervised Learning มีเพียงชุดของตัวแปรนำเข้า X1, X2, ..., Xp ที่วัดจาก n การสังเกต แต่ไม่มีตัวแปรผลลัพธ์ Y เป้าหมายคือการค้นหาข้อมูลเชิงลึกเกี่ยวกับตัวแปรนำเข้าเหล่านี้ เช่น การหากลุ่มที่คล้ายกันหรือโครงสร้างที่ซ่อนอยู่ในข้อมูล
ตัวอย่างปัญหาที่ใช้ Unsupervised Learning ได้
- การวิเคราะห์การจัดกลุ่ม (Cluster Analysis): ค้นหากลุ่มย่อยของตัวอย่างมะเร็งเต้านมโดยใช้ข้อมูลระดับการแสดงออกของยีน (Gene Expression Levels) โดยไม่มีตัวแปรผลลัพธ์ เป้าหมายคือการค้นหากลุ่มที่น่าสนใจในตัวอย่างหรือข้อมูลยีน
- การแบ่งกลุ่มลูกค้า (Customer Segmentation): วิเคราะห์ข้อมูลผู้ซื้อจากเว็บไซต์ช้อปปิ้งออนไลน์เพื่อจัดกลุ่มลูกค้าที่มีพฤติกรรมการเรียกดูและซื้อสินค้าที่คล้ายกัน (ไม่มีตัวแปรผลลัพธ์) เป้าหมายคือการค้นหารูปแบบในพฤติกรรมการซื้อ�สินค้า
- การจัดกลุ่มผลการค้นหา (Search Result Grouping): แสดงผลการค้นหาที่เหมาะสมกับแต่ละบุคคลโดยพิจารณาจากประวัติการคลิกของผู้ใช้ที่มีรูปแบบการค้นหาคล้ายกัน
- การวิเคราะห์องค์ประกอบหลัก (Principal Components Analysis - PCA): ใช้สำหรับการสร้างภาพข้อมูล (Data Visualization) หรือเป็นขั้นตอนก่อนการใช้เทคนิค Supervised Learning
สรุประหว่าง Supervised และ Unsupervised
Supervised Learning เปรียบเสมือนการเรียนรู้แบบมี "ครู" (ตัวแปรผลลัพธ์ Y) คอยชี้นำ ในขณะที่ Unsupervised Learning เป็นการเรียนรู้แบบไม่มีครู โดยมุ่งเน้นการค้นหารูปแบบและโครงสร้างในข้อมูลด้วยตัวเอง
- Supervised Learning ใช้เมื่อมีตัวแปรผลลัพธ์ (Response Variable) ที่กำกับกา��รเรียนรู้ เช่น การทำนายรายได้ หรือการจำแนกประเภทผู้ป่วย
- Unsupervised Learning ใช้เมื่อไม่มีตัวแปรผลลัพธ์ เป้าหมายคือการค้นหารูปแบบหรือโครงสร้างที่ซ่อนอยู่ในข้อมูล เช่น การแบ่งกลุ่มลูกค้าหรือการค้นหาความสัมพันธ์ระหว่างตัวแปร
Unsupervised Learning โดยทั่วไปถือว่า ท้าทายมากกว่า Supervised Learning เนื่องจาก:
- ใน Supervised Learning มี เป้าหมายที่ชัดเจน คือการพยากรณ์ค่าผลลัพธ์ (Response Variable) ซึ่งมีเครื่องมือและเทคนิคที่พัฒนาอย่างดี รวมถึงวิธีการประเมินคุณภาพของผลลัพธ์ สามารถตรวจสอบความแม่นยำของโมเดลได้โดยเปรียบเทียบค่าที่พยากรณ์กับค่าจริงของ Y บนชุดข้อมูลที่ไม่ได้ใช้ในการฝึกโมเดล
- ในทางกลับกัน Unsupervised Learning มักเป็น กระบวนการที่มีความเป็นอัตวิสัยมากกว่า (Subjective) เพราะ ไม่มีเป้าหมายที่แน่นอน เช่น การพยา��กรณ์ค่าผลลัพธ์ มักถูกใช้เป็นส่วนหนึ่งของ Exploratory Data Analysis ซึ่งมุ่งเน้นการค้นหารูปแบบและโครงสร้างในข้อมูล โดยไม่มีตัวแปรผลลัพธ์เป็นแนวทาง นอกจากนี้ การประเมินผลลัพธ์ของ Unsupervised Learning เป็นเรื่องที่ยากกว่า เนื่องจาก ไม่มีเกณฑ์ที่เป็นที่ยอมรับอย่างแพร่หลายสำหรับการตรวจสอบความถูกต้องของโมเดล เช่น การใช้ Cross-Validation หรือการทดสอบบนชุดข้อมูลอิสระ ในหลายกรณีเราอาจไม่ทราบ "คำตอบที่แท้จริง" ของข้อมูลที่กำลังวิเคราะห์
Linear Regression
Linear Regression เป็นวิธีที่เรียบง่ายใน Supervised Learning สำหรับการพยากรณ์ค่าผลลัพธ์เชิงปริมาณ โดยมีสมมติฐานว่ามี ความสัมพันธ์เชิงเส้น (Linear Relationship) ระหว่างตัวแปรนำเข้า X และตัวแปรผลลัพธ์ Y
แนวคิดสำ��คัญใน Linear Regression
- Simple Linear Regression: เป็นวิธีที่ใช้พยากรณ์ค่าผลลัพธ์เชิงปริมาณ Y โดยอาศัยตัวแปรนำเข้า X เพียงตัวเดียว โดยสมมติว่ามีความสัมพันธ์เชิงเส้น ซึ่งสามารถแสดงเป็นสมการ
โดยที่ β0 เป็นค่า Intercept และ β1 เป็นค่า Slope หรือความชันของเส้น
-
ในขั้นแรก ก่อนการคำนวณใด ๆ ค่าของ β0 และ β1 ยังไม่ทราบ เป้าหมายคือการประมาณค่าสัมประสิทธิ์เหล่านี้เพื่อให้โมเดลเชิงเส้นสามารถอธิบายข้อมูลที่มีอยู่ได้อย่างเหมาะสม
-
วิธีที่ใช้บ่อยที่สุดในการประมาณค่า β0 และ β1 คือ Ordinary Least Squares (OLS) โดยมีเป้าหมายเพื่อลดค่าผลรวมของกำลังสองของเศษเหลือ (Residual Sum of Squares หรือ RSS)
- Residual Sum of Squares (RSS) คือผลรวมของกำลังสองของความแตกต่างระหว่างค่าจริง (yi) และค่าที่คาดก�ารณ์ (ŷi) ดังนี้
-
วิธี OLS จะเลือกค่าของ และ ที่ทำให้ RSS มีค่าน้อยที่สุด ซึ่งหมายถึงการหาค่าที่เหมาะสมที่สุดของ และ เพื่อลดความคลาดเคลื่อนระหว่างค่าที่คาดการณ์และค่าจริง
-
สูตรการประมาณค่าสัมประสิทธิ์ (Coefficient Estimates Formulas): โดยใช้แคลคูลัส ค่าของ และ ที่ลดค่า RSS ได้มากที่สุดสามารถหาได้จากสูตรดังนี้:
โดยที่ x̄ และ ȳ คือค่าเฉลี่ยของ X และ Y ตามลำดับ
-
การตีความ (Interpretation):
- แทนค่า intercept ซึ่งเป็นค่าคาดหมายของ Y เมื่อ X = 0
- แทนค่า slope ซึ่งหมายถึงการเปลี่ยนแปลงเฉลี่ยของ Y ที่สัมพันธ์กับการเพิ่มขึ้นของ X ทีละ 1 หน่วย
-
- Multiple Linear Regression: เป็นการขยายแนวคิดของ Simple Linear Regression ให้รองรับตัวแปรนำเข้าหลายตัว ซึ่งสามารถเขียนเป็นสมการ โดยที่ X1, X2, ..., Xp เป็นตัวแปรพยากรณ์หลายตัว
- Estimating Coefficients: ค่าสัมประสิทธิ์ β0 และ β1 โดยทั่วไปเป็นค่าที่ไม่ทราบล่วงหน้าและต้องประมาณค่าจากข้อมูล วิธีที่นิยมใช้มากที่สุดคือการหาค่าที่ทำให้เกิด Least Squares Criterion ต่ำที่สุด
- Least Squares Approach: เป็นวิธีที่เลือกเส้นตรงที่ทำให้ Residual Sum of Squares (RSS) ต่ำที่สุด โดย RSS คือผลรวมของค่าความคลาดเคลื่อนระหว่างค่าที่สังเกตได้กับค่าที่พยากรณ์ได้
- Assessing Accuracy:
-
Residual Standard Error (RSE) ใช้ในการประมาณค่าความคลาดเคลื่อนของข้อผิดพลาดในโมเดล
-
R² Statistic วัดสัดส่วนของความแปรปรวนในตัวแปรผลลัพธ์ที่สามารถอธิบายได้โดยตัวแปรนำเข้า
- (Sum of Squares of Residuals) = ความคลาดเคลื่อนของค่าที่โมเดลทำนาย
- (Total Sum of Squares) = ความแปรปรวนรวมของข้อมูลจริง
- ค่าสถิติ R² ใช้เป็นตัววัดว่า โมเดลเชิงเส้นสามารถอธิบายข้อมูลได้ดีเพียงใด โดยให้ข้อมูลเชิงลึกเกี่ยวกับ สัดส่วนของความแปรปรวนในตัวแปรตอบสนองที่สามารถอธิบายได้โดยตัวแปรพยากรณ์
-
- อธิบายเพิ่มเติมเกี่ยวกับ
- ใกล้ 1 (ค่าสูง) หมายความว่า แบบจำลองสามารถอธิบายความแปรปรวนของตัวแปรตอบสนองได้เป็นสัดส่วนมาก แบบจำลองมีความพอดีกับข้อมูลสูง (Good Fit)
- ใกล้ 0 (ค่าต่ำ) หมายความว่า แบบจำลองไม่สามารถอธิบายความแปรปรวนของตัวแปรตอบสนองได้ดี แบบจำลองไม่พอดีกับข้อมูล (Poor Fit)
- ค่า จะเพิ่มขึ้นเสมอเมื่อมีการเพิ่มตัวแปรทำนายเข้าไปในแบบจำลอง แม้ว่าตัวแปรเหล่านั้นจะมีความสัมพันธ์ที่อ่อนกับตัวแปรตอบสนอง
- Adjusted ช่วยแก้ปัญหานี้โดยปรับค่า ให้คำนึงถึงจำนวนตัวแปรในแบบจำลอง เพื่อป้องกันการเพิ่มตัวแปรที่ไม่จำเป็น (โดยใช้วิธีการลงโทษ (penalty) สำหรับการเพิ่มตัวแปรที่ไม่จำเป็นในโมเดล)
-
R² มักจะเพิ่มขึ้นเสมอ: R² จะเพิ่มขึ้นเมื่อมีการเพิ่มตัวแปรใหม่เข้าไปในโมเดล แม้ว่าตัวแปรเหล่านั้นจะมีความสัมพันธ์เพียงเล็กน้อยหรือไม่มีเลยกับตัวแปรเป้าหมาย การเพิ่มตัวแปรจะทำให้ Residual Sum of Squares (RSS) ลดลงเสมอสำหรับข้อมูลชุดฝึก (training data) เนื่องจาก R² = 1 - RSS/TSS เมื่อ RSS ลดลง ค่า R² ก็จะเพิ่มขึ้นเสมอc มีการลงโทษ: ค่าสถิติ Adjusted R² ต่างจาก R² ตรง�ที่มันจะพิจารณาจำนวนตัวแปร (predictors) ในโมเดลด้วย
- n คือจำนวนข้อมูลสังเกต (observations)
- d คือจำนวนตัวแปร (predictors) ในโมเดล
- RSS คือ Residual Sum of Squares
- TSS คือ Total Sum of Squares
-
ผลของการลงโทษ: แม้ว่า RSS จะลดลงเสมอเมื่อมีการเพิ่มจำนวนตัวแปรในโมเดล แต่พจน์ RSS/(n-d-1) อาจเพิ่มขึ้นหรือลดลงขึ้นอยู่กับค่า d ในตัวหาร การเพิ่มตัวแปรที่ไม่มีประโยชน์ (noise variables) จะทำให้ค่า d เพิ่มขึ้น ซึ่งจะส่งผลให้ค่า RSS/(n-d-1) เพิ่มขึ้น และทำให้ค่า Adjusted R² ลดลงในที่สุด
-
การเลือกโมเดล: เป้าหมายคือการเพิ่มค่า Adjusted R² ให้มากที่สุด ซึ่งเทียบเท่ากับการทำให้ค่า RSS/(n-d-1) น้อยที่สุด โมเดลที่มีค่า Adjusted R² มากที่สุดมักจะเป็นโมเดลที่รวมตัวแปรที่เหมาะสมทั้งหมดและตัดตัวแปรที่ไม่จำเป็นออกไป
-
- Population Regression Line: เส้นที่ดีที่สุดที่ประมาณความสัมพันธ์ที่แท้จริงระหว่าง X และ Y
- Qualitative Predictors: โมเดล Linear Regression สามารถขยายเพื่อรองรับตัวแปรนำเข้าที่เป็น Qualitative Predictors ได้ เช่น การใช้ตัวแปรหมวดหมู่ (Categorical Variables) โดยการแปลงเป็น Dummy Variables
ตัวอย่างปัญหา Linear Regression ใน Python
ปัญหา: การพยากรณ์จำนวนไมล์ต่อแกลลอน (mpg) ของรถยนต์ (รถคันนั้นสามารถวิ่งได้กี่ไมล์ต่อแกลลอนน้ำมัน 1 แกลลอน) โดยใช้แรงม้า (horsepower) (อัตราการทำงานของเ�ครื่องยนต์ในการเคลื่อนที่รถยนต์ต่อหน่วยเวลา)
- จำนวนไมล์ต่อแกลลอน (miles per gallon - mpg) เป็นตัวชี้วัด อัตราการใช้เชื้อเพลิง ของรถยนต์ โดยแสดงให้เห็นว่า รถยนต์สามารถวิ่งได้กี่ไมล์ต่อเชื้อเพลิง 1 แกลลอน ซึ่งยิ่งค่า mpg สูงเท่าไหร่ แสดงว่ารถยนต์ใช้เชื้อเพลิงได้มีประสิทธิภาพมากขึ้น หรือก็คือ ประหยัดน้ำมันมากขึ้น
- โดยทั่วไปแล้ว ยิ่งแรงม้ามาก ค่า MPG มักจะต่ำลง เนื่องจากรถยนต์ที่มีกำลังสูงจะใช้เชื้อเพลิงมากขึ้นเพื่อสร้างแรงขับเคลื่อนที่สูงขึ้น
วัตถุประสงค์: พัฒนาโมเดล Linear Regressionแบบง่ายเพื่อพยากรณ์ประสิทธิภาพการใช้เชื้อเพลิงของรถยนต์ (mpg) โดยอาศัยแรงม้า (horsepower) เป็นตัวแปรทำนาย ซึ่งจะช่วยให้สามารถวัดความสัมพันธ์ระหว่างแรงม้ากับ mpg และประเมินประสิทธิภาพของโมเดลได้
ข้อมูลหยิบมาจาก https://pypi.org/project/ISLP/
ตัวอย่าง code Python
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
import numpy as np
from ISLP import load_data
from ISLP.models import ModelSpec as MS, summarize
# โหลดชุดข้อมูล Auto
Auto = load_data('Auto')
# ลบแถวที่มีค่าว่าง
Auto = Auto.dropna()
# Linear Regressionแบบง่าย
# สร้างเมทริกซ์ของตัวแปรอิสระ (X)
X = pd.DataFrame({'intercept': np.ones(len(Auto)), 'horsepower': Auto['horsepower']})
# กำหนดตัวแปรตาม (y)
y = Auto['mpg']
# สร้างโมเดล
model = sm.OLS(y, X)
results = model.fit()
# แสดงผลสรุปของโมเดล
print(summarize(results))
# โค้ดด้านล่างสามารถใช้ตอบคำถามย่อยของปัญหา
# i. มีความสัมพันธ์ระหว่างตัวแปรอิสระและตัวแปรตามหรือไม่?
# - ใช้ค่า p-value จาก summarize() เพื่อตรวจสอบ
# ii. ความสัมพันธ์ระหว่างตัวแปรอิสระและตัวแปรตามแข็งแกร่งเพียงใด?
# - พิจารณาค่า R-squared จาก summarize()
# iii. ความสัมพันธ์เป็นเชิงบวกหรือเชิงลบ?
# - ตรวจสอบเครื่องหมายของค่าสัมประสิทธิ์ของ horsepower
# iv. ค่าพยากรณ์ mpg สำหรับรถที่มีแรงม้า 98 เท่ากับเท่าไร?
# ค่าช่วงความเชื่อมั่น 95% และค่าพยากรณ์ช่วง 95% เป็นเท่าไร?
# - ใช้ results.get_prediction() เพื่อคำนวณค่าพยากรณ์และช่วงความเชื่อมั่น
# สร้าง DataFrame ใหม่สำหรับค่าที่ต้องการพยากรณ์
new_df = pd.DataFrame({'horsepower': [98]})
# เพิ่มค่า intercept
new_df['intercept'] = 1
# จัดลำดับคอลัมน์ให้ตรงกับข้อมูลที่ใช้ฝึกโมเดล
new_df = new_df[['intercept', 'horsepower']]
# ใช้โมเดลในการพยากรณ์ค่า mpg
predictions = results.get_prediction(new_df)
# แสดงค่าพยากรณ์เฉลี่ย
print(predictions.predicted_mean)
# แสดงช่วงความเชื่อมั่น 95%
print(predictions.conf_int(alpha=0.05))
# สร้าง scatter plot ของ mpg กับ horsepower พร้อมเส้นถดถอย
plt.figure(figsize=(8, 6))
plt.scatter(Auto['horsepower'], Auto['mpg'], label='Data')
# สร้างค่าของ horsepower สำหรับเส้นถดถอย
x_plot = np.linspace(Auto['horsepower'].min(), Auto['horsepower'].max(), 100)
# สร้าง DataFrame สำหรับค่าที่ใช้สร้างเส้นถดถอย
X_plot = pd.DataFrame({'intercept': np.ones(100), 'horsepower': x_plot})
# พยากรณ์ค่า mpg สำหรับค่า horsepower ต่างๆ
y_plot = results.predict(X_plot)
# วาดเส้นถดถอย
plt.plot(x_plot, y_plot, color='red', label='Regression Line')
# กำหนดป้ายกำกับและชื่อกราฟ
plt.xlabel('Horsepower')
plt.ylabel('MPG')
plt.title('MPG vs Horsepower with Regression Line')
# แสดงคำอธิบาย
plt.legend()
# แสดงกราฟ
plt.show()
# แสดง Diagnostic Plots
plt.figure(figsize=(12, 6))
# กราฟ Residuals vs. Fitted Values
plt.subplot(1, 2, 1)
plt.scatter(results.fittedvalues, results.resid)
plt.xlabel('Fitted Values')
plt.ylabel('Residuals')
plt.title('Residuals vs. Fitted Values')
plt.axhline(y=0, color='r', linestyle='--') # เส้นแนวนอนที่ y=0
# ฮิสโตแกรมของ Residuals
plt.subplot(1, 2, 2)
plt.hist(results.resid, bins=30)
plt.xlabel('Residuals')
plt.ylabel('Frequency')
plt.title('Histogram of Residuals')
plt.tight_layout()
plt.show()
คำอธิบาย code
- โหลดและเตรียมข้อมูล:
- โหลดชุดข้อมูล
Auto - ลบแถวที่มีค่าหายไป (
dropna())
- โหลดชุดข้อมูล
- กำหนดโมเดล:
- เพิ่มค่า intercept ให้กับตัวแปรอิสระ
- ใช้
horsepowerเป็นตัวแปรอิสระ และmpgเป็นตัวแปรตาม
- สร้างและปรับโมเดล:
- ใช้ฟังก์ชัน
sm.OLS()จากstatsmodelsเพื่อตั้งค่า Linear Regression - คำสั่งนี้ ช้สำหรับสร้างและฝึกโมเดล Linear Regression ด้วยวิธี Ordinary Least Squares (OLS) โดยหลักการของ OLS คือการหาค่าสัมประสิทธิ์ (coefficients) ของสมการเชิงเส้นที่ทำให้ผลรวมกำลังสองของ Residuals น้อยที่สุด
- ใช้
.fit()เพื่อฝึกโมเดล
- ใช้ฟังก์ชัน
- วิเคราะห์ผลลัพธ์ของโมเดล:
- ใช้ฟังก์ชัน
summarize()เพื่อดูค่าสัมประสิทธิ์ ค่าความเชื่อมั่น และค่า p-value
- ใช้ฟังก์ชัน
- ทำการพยากรณ์:
- คำนวณค่า
mpgสำหรับรถที่มีแรงม้า 98 - แสดงช่วงความเชื่อมั่น 95%
- คำนวณค่า
- สร้างกราฟการถดถอย:
- วาด scatter plot ของ
mpgกับhorsepower - วาดเส้นถดถอยที่ได้จากโมเดล
- วาด scatter plot ของ
- สร้าง Diagnostic Plots เพื่อประเมินความเหมาะสมของโมเดล:
- กราฟ Residuals vs Fitted Values เพื่อตรวจสอบแนวโน้มของข้อผิดพลาด
- ฮิสโตแกรมของ residuals เพื่อตรวจสอบการแจกแจงของข้อผิดพลาด
ผลลัพธ์
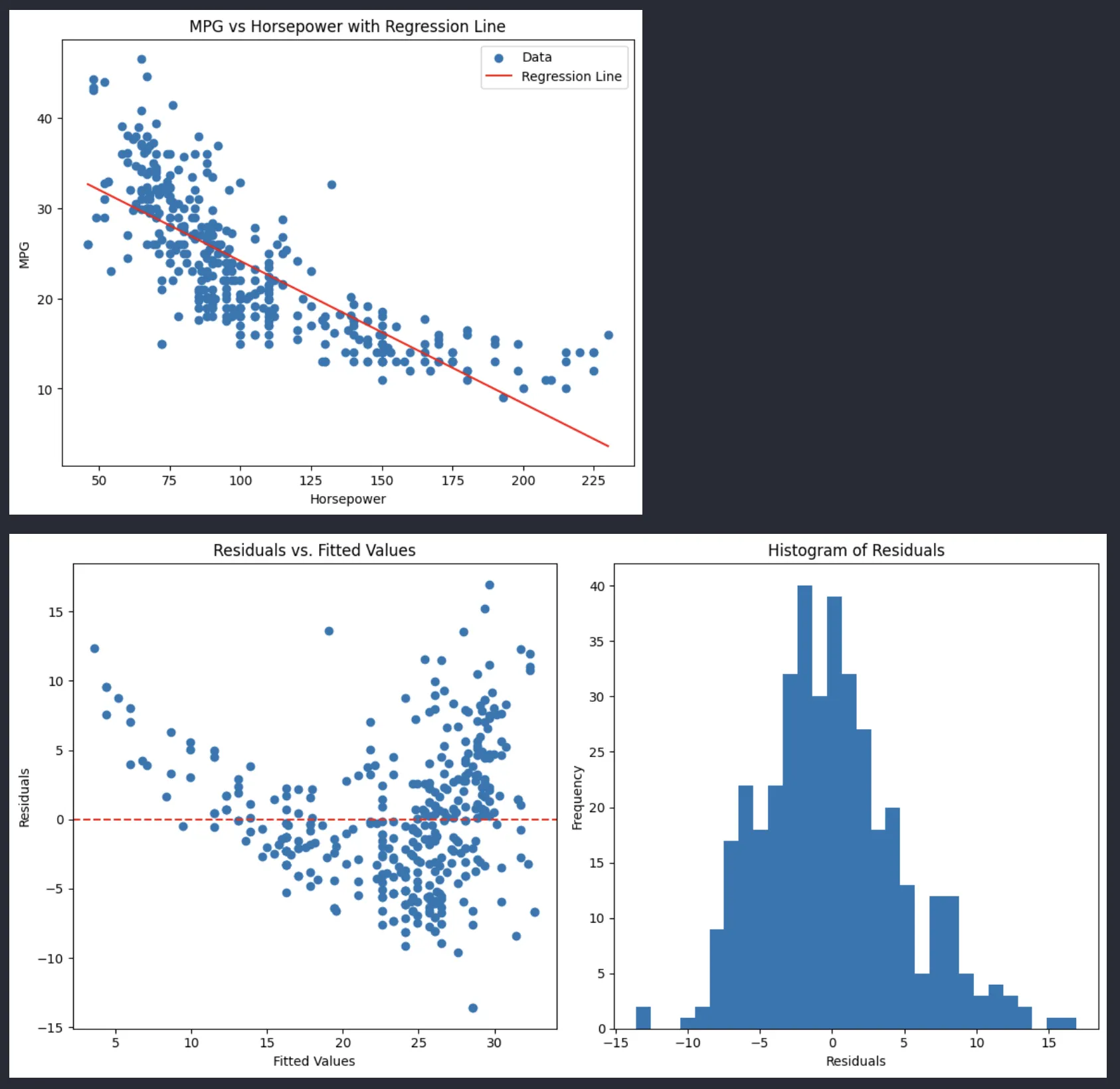
จากกราฟเราจะได้ผลลัพธ์ออกมา 3 กราฟคือ
- กราฟแรก (MPG vs Horsepower with Regression Line):
- แสดงความสัมพันธ์ระหว่างอัตราการประหยัดน้ำมัน (MPG) กับกำลังเครื่องยนต์ (Horsepower)
- เส้นสีแดงคือเส้น Regression Line แสดงแนวโน้มความสัมพันธ์
- มีความสัมพันธ์เชิงลบ (negative correlation) คือเมื่อ Horsepower เพิ่มขึ้น MPG จะลดลง
- จุดข้อมูล (สีน้ำเงิน) กระจายตัวรอบๆ เส้น regression แสดงว่ามีความแปรปรวนในข้อมูล
- กราฟที่สอง (Residuals vs. Fitted Values):
- แสดง residuals (ค่าความคลาดเคลื่อน) เทียบกับค่าที่ทำนายได้ (fitted values)
- เส้นประสีแดงที่ y=0 แสดงจุดที่การทำนายแม่นยำที่สุด
- การกระจายตัวของจุดไม่เป็นรูปแบบที่ชัดเจน แต่มีแนวโน้มที่จุดกระจายมากขึ้นเมื่อ fitted values สูงขึ้น
- แสดงว่าโมเดลอาจมี heteroscedasticity (ความแปรปรวนไม่คงที่)
- กราฟที่สาม (Histogram of Residuals):
- แสดงการกระจายตัวของ residuals
- Residuals หมายถึง ค่าความต่างระหว่างค่าจริง (Observed Value) กับค่าที่โมเดลพยากรณ์ (Predicted Value) สำหรับแต่ละจุดข้อมูล
- รูปร่างคล้ายการแจกแจงแบบปกติ (normal distribution) แต่มีความเบ้เล็กน้อย
- ส่วนใหญ่ของ residuals อยู่ในช่วง -5 ถึง 5
- การที่กราฟมีลักษณะใกล้เคียงการแจกแจงแบบปกติแสดงว่าโมเดลมีความเหมาะสมในระดับหนึ่ง
- แสดงการกระจายตัวของ residuals
โดยสรุป โมเดลนี้แสดงให้เห็นว่ามีความสัมพันธ์เชิงลบระหว่าง MPG และ Horsepower แต่อาจมีปัญหาเรื่อ��ง heteroscedasticity ที่ควรระวังในการนำไปใช้ทำนาย แต่อย่างที่เห็น จาก code นี้ช่วยให้เราสามารถสำรวจความสัมพันธ์ระหว่าง horsepower และ mpg ได้ โดย
- ตรวจสอบความมีนัยสำคัญของตัวแปร (
p-value) - ประเมินความสามารถในการอธิบายของโมเดล (
R-squared) - ตรวจสอบทิศทางของความสัมพันธ์ (เชิงบวกหรือเชิงลบ)
- ใช้โมเดลเพื่อพยากรณ์ค่า
mpgและแสดงช่วงความเชื่อมั่น