Classification
รู้จักกับ Classification
ปัญหาการจัดประเภท (Classification Problem) คือปัญหาที่เกี่ยวข้องกับการคาดการณ์ ค่าตอบสนองเชิงคุณภาพ (หรือที่เรียกว่าข้อมูลประเภทหมวดหมู่) ซึ่งตัวแปรสามารถมีค่าอยู่ในหนึ่งใน K หมวดหมู่ที่แตกต่างกัน เป้าหมายคือการกำหนดว่าข้อมูลที่ได้รับควรถูกจัดให้อยู่ในหมวดหมู่หรือคลาสใด
ตัวอย่างของปัญหาการจัดประเภท ได้แก่
- การวินิจฉัยทางการแพทย์ (Medical Diagnosis): กำหนดว่าบุคคลมีโรคใดในสามโรคที่เป็นไปได้ โดยอ้างอิงจากชุดของอาการที่พบ
- การตรวจจับการฉ้อโกง (Fraud Detection): พิจารณาว่าธุรกรรมธนาคารออนไลน์เป็นการฉ้อโกงหรือไม่ โดยอ้างอิงจากที่อยู่ IP ของผู้ใช้และประวัติธุรกรรมที่ผ่านมา
- การวิเคราะห์การกล�ายพันธุ์ของ DNA (DNA Mutation Analysis): จำแนกว่าการกลายพันธุ์ของ DNA ใดเป็นสาเหตุของโรค และการกลายพันธุ์ใดไม่มีผลกระทบ โดยอ้างอิงจากข้อมูลลำดับ DNA
- การวิเคราะห์อารมณ์ (Sentiment Analysis): จำแนกรีวิวภาพยนตร์ใน IMDB ว่าเป็นรีวิวเชิงบวกหรือเชิงลบ
- การพยากรณ์การผิดนัดชำระหนี้ (Default Prediction): พิจารณาว่าบุคคลจะผิดนัดชำระหนี้บัตรเครดิตหรือไม่
- การจัดประเภทภาพ (Image Classification): จำแนกประเภทของภาพ เช่น ภาพจากชุดข้อมูล CIFAR100
- การวินิจฉัยโรคมะเร็ง (Cancer Diagnosis): กำหนดว่ามะเร็งที่พบในเซลล์เป็นชนิดใด
ทีนี้จากที่เราเรียกมาก่อนหน้า เราเรียนเรื่อง Linear Regression มาเอาจริงๆ หากเราประยุกต์ใช้หน่อย โดยการพยายามดัดแปลงค่าของ Linear Regression ให้สามารถตีความค่าเป็นกลุ่มได้ จริงๆก็สามารถนำมาประยุกต์ใช้กับโจทย์ปัญหา Classification ได้ แต่ในทางการใช้งานจริง เรากลับค้นพบปัญหาตามมาเมื่อพยายามใช้ด้วย Linear Regression ตั้งแต่
- ลักษณะของตัวแปรตอบสนอง: Linear Regression ตั้งสมมติฐานว่าตัวแปรตอบสนองเป็นเชิงปริมาณ ในขณะที่ปัญหาการจัดประเภทเกี่ยวข้องกับค่าตอบสนองเชิงคุณภาพ
- การตีความผลลัพธ์: Linear Regression สามารถให้ค่าพยากรณ์ที่อยู่นอกช่วง 0 และ 1 ซึ่งทำให้การตีความเป็นความน่าจะเป็นในบริบทของการจัดประเภททำได้ยาก
- การแปลงค่าตอบสนองเชิงคุณภาพ: แม้ว่าจะสามารถสร้างตัวแปร Dummy เพื่อแทนค่าข้อมูลเชิงคุณภาพได้ แต่การเปลี่ยนข้อมูลประเภทนี้ให้เป็นข้อมูลเชิงปริมาณสำหรับLinear Regression อาจไม่ให้แบบจำลองที่มีประสิทธิภาพ
วิธีที่เหมาะสมกว่าสำหรับปัญหาการจัดประเภท
- Logistic Regression: ใช้แบบจำลองความน่าจะเป็นเพื่อกำหนดว่าข้อมูลอยู่ในหมวดหมู่ใด
- Linear Discriminant Analysis (LDA): ใช้ฟังก์ชันเชิงเส้นของตัวแปรอิสระ��เพื่อจัดประเภทข้อมูล
- Quadratic Discriminant Analysis (QDA)
- Naive Bayes: จำแนกข้อมูลโดยสมมติว่าตัวแปรอิสระมีความเป็นอิสระต่อกันภายในแต่ละคลาส
- K-Nearest Neighbors (KNN): จัดประเภทข้อมูลโดยอิงจากคลาสของเพื่อนบ้านที่ใกล้ที่สุด k ตัว
- Tree-Based Methods: ใช้ Decision Tree ในการจำแนกประเภท
- Support Vector Machines (SVM)
- Generalized Additive Models (GAMs): สามารถใช้สำหรับปัญหาการจัดประเภท
- Neural Networks: ใช้โครงข่ายประสาทเทียมในการเรียนรู้รูปแบบของข้อมูล
เราจะมาเรียนรู้จาก Logistic Regression ซึ่งถือเป็นพื้นฐานแรกสุดของการทำ Classification กัน
Logistic Regression
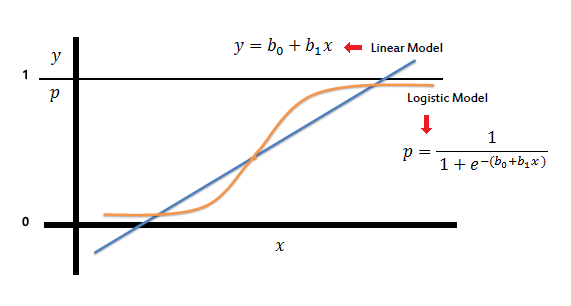
Logistic Regression เป็นวิธีการจัดหมวดหมู่ที่ใช้ในการทำนายค่าตอบสนองเชิงคุณภาพ แทนที่จะสร้างโมเดลค่าตอบสนองโดยตรง มันจะสร้างโมเดลของความน่าจะเป็นที่ค่าตอบสนองจะอยู่ในหมวดหมู่ใดหมวดหมู่หนึ่ง
ref: https://www.saedsayad.com/logistic_regression.htm
องค์ประกอบสำคัญของ Logistic Regression
- ค่าตอบสนองเชิงคุณภาพ (Qualitative Response): Logistic Regression ถูกออกแบบมาสำหรับกรณีที่ตัวแปรเป้าหมายเป็นค่าหมวดหมู่ที่ชัดเจน เช่น "ใช่" หรือ "ไม่ใช่"
- การสร้างโมเดลความน่าจะเป็น (Probability Modeling): โมเดลนี้ใช้ทำนาย ค่าความน่าจะเป็น ที่ค่าตอบสนองจะตกอยู่ในหมวดหมู่ใดหมวดหมู่หนึ่ง เช่น ความน่าจะเป็นที่ลูกค้าจะผิดนัดชำระหนี้โดยพิจารณาจากยอดคงเหลือในบัญชี
- Logistic Function : ใช้ Logistic Function เพื่อให้ค่าความน่าจะเป็นที่ได้อยู่ระหว่าง 0 ถึง 1 เสมอ โดยมีสมการดังนี้
- Log Odds หรือ Logit: โมเดลนี้ใช้การแปลงค่าความน่าจะเป็นให้อยู่ในรูป log odds ซึ่งเป็นค่าที่เป็นเส้นตรงกับ X การเพิ่มค่า X ขึ้นหนึ่งหน่วยจะทำให้ log odds เปลี่ยนไปตามค่า
- การประมาณค่าสัมประสิทธิ์ (Estimating Coefficients): ใช้วิธี Maximum Likelihood Estimation (MLE) เพื่อหาค่าสัมประสิทธิ์ที่ทำให้ความน่าจะเป็นของข้อมูลจริงมากที่สุด
- ตัวแปรพยากรณ์หลายตัว (Multiple Predictors): Logistic Regression สามารถขยายไปใช้กับหลายตัวแปรได้ เช่นเดียวกับLinear Regression พหุคูณ (Multiple Linear Regression)
- ตัวแปรพยากรณ์เชิงคุณภาพ (Qualitative Predictors): สามารถรวมตัวแปรพยากรณ์เชิงคุณภาพเข้าไปในโมเดลได้โดยใช้ ตัวแปรดัมมี่ (Dummy Variables)
- Logistic Regression แบบพหุหมวดหมู่ (Multinomial Logistic Regression): เป็นการขยายLogistic Regression เพื่อรองรับค่าตอบสนองที่มีมากกว่าสองหมวดหมู่
Logistic Regression เป็นหนึ่งในเทคนิคการจัดหมวดหมู่ที่ได้รับความนิยม เนื่องจากสามารถตีความได้ง่ายและมีความยืดหยุ่นในการใช้งานกับข้อมูลที่หลากหลาย
ตัวอย่างปัญหาที่ใช้ Logistic Regression
โจทย์: การทำนายการผิดนัดชำระบัตรเครดิต
ลองพิจารณาชุดข้อมูล เช่น ชุดข้อมูล "Default" ซึ่งมีเป้าหมายเพื่อทำนายว่าลูกค้าจะ ผิดนัดชำระ บัตรเครดิตหรือไม่ ("Yes" หรือ "No") โดยพิจารณาจาก ยอดคงเหลือในบัญชี (Balance)
แนวคิดและการคำนวณ
-
แกนหลักของLogistic Regression คือการสร้างโมเดลค่าความน่าจะเป็นของการผิดนัดชำระโดยใช้ Logistic Function
โดยที่
- คือความน่าจะเป็นของการผิดนัดชำระ
- คือยอดคงเหลือในบัญชี (Balance)
- และ เป็นสัมประสิทธิ์ที่ต้องประมาณค่า
-
การประมาณค่าสัมประสิทธิ์ ค่าสัมประสิทธิ์ และ จะถูกประมาณโดยใช้ Maximum Likelihood Estimation (MLE) ซึ่งเป็นวิธีที่ช่วยหาค่าพารามิเตอร์ที่ทำให้ฟังก์ชันความน่าจะเป็นของข้อมูลจริงมากที่สุด โดยทั่วไปซอฟต์แวร์สถิติจะใช้วิธีนี้ในการคำนวณ
-
การทำนาย (Making Predictions)
- เมื่อได้ค่าพารามิเตอร์แล้ว สามารถใช้โมเดลในการทำนายค่าความน่าจะเป็นของการผิดนัดชำระสำหรับลูกค้ารายใหม่
- หากค่าความน่าจะเป็นมากกว่าค่าที่กำหนดเป็นเกณฑ์ (เช่น 0.5) ลูกค้าจะถูกจัดให้อยู่ในกลุ่ม Default = Yes
-
การตีความสัมประสิทธิ์
- แสดงถึง การเปลี่ยนแปลงของ log odds ของการผิดนัดชำระเมื่อลูกค้ามียอดคงเหลือเพิ่มขึ้นหนึ่งหน่วย
- บอกถึงการเปลี่ยนแปลงแบบทวีคูณของ อัตราส่วนโอกาส (Odds Ratio) ของการผิดนัดชำระเมื่อลูกค้ามียอดคงเหลือเพิ่มขึ้นหนึ่งหน่วย
เมื่อลองใช้กับ python code ตัวอย่างนี้ใช้ statsmodels เพื่อนำ Logistic Regression มาสร้างโมเดล
import pandas as pd
import statsmodels.api as sm
from ISLP import load_data
# โหลดชุดข้อมูล Default
Default = load_data("Default")
# สร้างตัวแปรดัมมี่สำหรับสถานะนักเรียน (Student)
Default['student_yes'] = Default.student.map({'Yes': 1, 'No': 0})
# กำหนดตัวแปรพยากรณ์ (Predictors) และตัวแปรเป้าหมาย (Response Variable)
X = Default[['balance', 'income', 'student_yes']] # ตัวแปรพยากรณ์
y = Default['default'] == 'Yes' # แปลงค่าตัวแปรเป้าหมายเป็นค่าไบนารี (True = Default)
# สร้างโมเดลLogistic Regression
model = sm.GLM(y, sm.add_constant(X), family=sm.families.Binomial()) # ใช้ family=Binomial() สำหรับ Logistic Regression
results = model.fit()
# แสดงผลลัพธ์ของโมเดล
print(results.summary())
# การทำนายค่าความน่าจะเป็นของลูกค้ารายใหม่
new_data = pd.DataFrame({
'const': [1], # Add constant term first
'balance': [1500],
'income': [40000],
'student_yes': [0]
}) # ข้อมูลลูกค้าใหม่
predictions = results.predict(new_data) # No need to add constant since we already included it
print(predictions)
การอธิบาย code
- การโหลดข้อมูล: ใช้
load_data("Default")เพื่อโหลดชุดข้อมูล (เปลี่ยนจากปกติที่เราใช้ csv) - การเตรียมข้อมูล:
- กำหนด ตัวแปรพยากรณ์ ได้แก่
balance,income, และstudent_yes - แปลงค่าตัวแปรเป้าหมาย (
default) ให้เป็นค่าทางตรรกะ (TrueหรือFalse)
- กำหนด ตัวแปรพยากรณ์ ได้แก่
- การสร้างโมเดล: ใช้
statsmodelsเพื่อสร้าง model Logistic Regression โดยกำหนดให้เป็น Binomial Family - การทำนาย
- ใช้
results.predict()เพื่อทำนายค่าความน่าจะเป็นของลูกค้ารายใหม่ - ค่าที่ได้คือ ค่าความน่าจะเป็นของการผิดนัดชำระ
- ใช้
ผลลัพธ์
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: default No. Observations: 10000
Model: GLM Df Residuals: 9996
Model Family: Binomial Df Model: 3
Link Function: Logit Scale: 1.0000
Method: IRLS Log-Likelihood: -785.77
Date: Sat, 15 Feb 2025 Deviance: 1571.5
Time: 13:53:57 Pearson chi2: 7.00e+03
No. Iterations: 9 Pseudo R-squ. (CS): 0.1262
Covariance Type: nonrobust
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
const -10.8690 0.492 -22.079 0.000 -11.834 -9.904
balance 0.0057 0.000 24.737 0.000 0.005 0.006
income 3.033e-06 8.2e-06 0.370 0.712 -1.3e-05 1.91e-05
student_yes -0.6468 0.236 -2.738 0.006 -1.110 -0.184
===============================================================================
0 0.104992
dtype: float64
อธิบาย��ผลลัพธ์
- Model Family: Binomial และใช้ Link Function แบบ Logit
- การวิเคราะห์ตัวแปรอิสระ
- a) balance (ยอดคงเหลือ)
- coefficient = 0.0057
- p-value < 0.001 (มีนัยสำคัญทางสถิติ)
- เมื่อ balance เพิ่มขึ้น 1 หน่วย โอกาสการ default จะเพิ่มขึ้น (เนื่องจากค่า coefficient เป็นบวก)
- b) income (รายได้)
- coefficient = 3.033e-06 (ค่าน้อยมาก)
- p-value = 0.712 (ไม่มีนัยสำคัญทางสถิติ เพราะมากกว่า 0.05)
- รายได้ไม่มีผลอย่างมีนัยสำคัญต่อการ default
- c) student_yes (สถานะการเป็นนักเรียน)
- coefficient = -0.6468
- p-value = 0.006 (มีนัยสำคัญทางสถิติ)
- การเป็นนักเรียนมีผลในทางลบต่อการ default (ลดโอกาสการ default)
- a) balance (ยอดคงเหลือ)
- ค่าเฉลี่ยของการทำนายโอกาสการ default อยู่ที่ประมาณ 0.105 หรือ 10.5%
- Pseudo R-squared: 0.1262 (12.62% ของความแปรปรวนในข้อมูลสามารถอธิบายได้ด้วยโมเดลนี้)
- ค่าที่ค่อนข้างต่ำ (12.62%) บ่งชี้ว่าโมเดลนี้อาจจะยังไม่เหมาะสมเท่าที่ควรในการทำนายการ default
- อาจมีปัจจัยสำคัญอื่นๆ ที่ส่งผลต่อการ default แต่ไม่ได้ถูกรวมอยู่ในโมเดล เช่น:
- ประวัติการชำระเงิน
- อายุของลูกค้า
- ระยะเวลาการเป็นลูกค้า
- สถานภาพการทำงาน
- ประวัติเครดิต
โดยสรุป ปัจจัยที่มีผลอย่างมีนัยสำคัญต่อการ default คือ ยอดคงเหลือ (balance) และสถานะการเป็นนักเรียน (student) ในขณะที่รายได้ (income) ไม่มีผลอย่างมีนัยสำคัญ โมเดลนี้สามารถอธิบายความแปรปรวนของข้อมูลได้ประมาณ 12.62%
Naive Bayes classifier
ref: https://www.geeksforgeeks.org/naive-bayes-classifiers/
Naive Bayes Classifier เป็นวิธีการจำแนกประเภทที่ใช้ ทฤษฎีบทของเบย์ (Bayes’ Theorem) ในการประมาณความน่าจะเป็นของแต่ละคลาสเมื่อกำหนดค่าของตัวทำนาย (Predictors) แทนที่จะคำนวณค่าความน่าจะเป็นแบบปรับป�รุง (Posterior Probability) โดยตรง Naive Bayes Classifier จะทำการประมาณการกระจายของตัวทำนายก่อน จากนั้นจึงใช้ทฤษฎีบทของเบย์เพื่อคำนวณ
จุดสำคัญของ Naive Bayes Classifier
- ค่าความน่าจะเป็นล่วงหน้า (Prior Probabilities) จะถูกประมาณโดยคำนวณจากสัดส่วนของข้อมูลฝึกสอนที่อยู่ในคลาสที่ k
- ตัวจำแนกประเภทนี้ทำให้การประมาณค่าของ ง่ายขึ้นโดยสมมติว่า ตัวทำนายทั้งหมดเป็นอิสระต่อกันภายในแต่ละคลาส
- ภายใต้ส��มมติฐานของความเป็นอิสระ ความน่าจะเป็นแบบปรับปรุง (Posterior Probability) สามารถเขียนเป็น
สำหรับ
- หากตัวทำนาย เป็นตัวแปรเชิงปริมาณ (Quantitative Variable) สามารถสมมติได้ว่า ซึ่งเป็นการแจกแจงแบบปกติ (Gaussian Distribution)
- หาก เป็นตัวแปรเชิงคุณภาพ (Qualitative Variable) สามารถคำน��วณสัดส่วนของข้อมูลฝึกสอนที่แต่ละค่าของตัวทำนายปรากฏในแต่ละคลาส
แม้ว่าการสมมติว่าตัวทำนายเป็นอิสระต่อกันมักจะไม่เป็นจริงในทางปฏิบัติ แต่สมมติฐานนี้ช่วยให้การคำนวณง่ายขึ้น และสามารถให้ผลลัพธ์ที่ดี โดยเฉพาะเมื่อจำนวนข้อมูลฝึกสอนมีขนาดไม่ใหญ่มากเมื่อเทียบกับจำนวนตัวทำนาย แม้ว่า Naive Bayes จะตั้งสมมติฐานเพื่อความสะดวก แต่ก็มักให้ผลลัพธ์ที่ดีเพราะช่วยลดความแปรปรวนของแบบจำลอง
Naive Bayes สามารถใช้ได้กับทั้งตัวทำนายเชิงคุณภาพและเชิงปริมาณ โดย
- สำหรับ ตัวทำนายเชิงปริมาณ มักสมมติให้มีการแจกแจงแบบ Gaussian
- สำหรับ ตัวทำนายเชิงคุณภาพ สามารถใช้การนับสัดส่วนของข้อมูลฝึกสอนที่อยู่ในแต่ละคลาสเพื่อคำนวณค่าความน่าจะเป็น
Naive Bayes เป็นวิธีที่เรียบง่ายแต่ทรงพลัง และมักถูกใช้ในงานที่เกี่ยวข้องกับ การจำ��แนกประเภท (Classification) เช่น การจำแนกอีเมลสแปม, การวิเคราะห์ข้อความ และการตรวจจับความรู้สึก (Sentiment Analysis)
ตัวอย่างปัญหา
ในตัวอย่างนี้ เราจะใช้ Naive Bayes Classifier จาก sklearn.naive_bayes เพื่อจำแนกทิศทางของตลาดหุ้น (Direction: Up หรือ Down) โดยใช้ชุดข้อมูล Smarket ซึ่งประกอบด้วยตัวทำนายเชิงปริมาณ เช่น Lag1, Lag2 (ผลตอบแทนของตลาดในวันก่อนหน้า)
code python
import pandas as pd
import numpy as np
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# โหลดข้อมูล Smarket จาก ISLP package
from ISLP import load_data
smarket = load_data('Smarket')
# แสดงตัวอย่างข้อมูล
print(smarket.head())
# แปลงค่าตัวแปรเป้าหมาย ('Direction') เป็นตัวเลข (Up -> 1, Down -> 0)
smarket['Direction'] = smarket['Direction'].map({'Up': 1, 'Down': 0})
# เลือกเฉพาะตัวแปรเชิงปริมาณเป็นตัวทำนาย (Lag1, Lag2)
X = smarket[['Lag1', 'Lag2']]
y = smarket['Direction']
# แบ่งข้อมูลเป��็นชุดฝึก (80%) และชุดทดสอบ (20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# แสดงขนาดของชุดข้อมูลที่แบ่งแล้ว
print(f"Training set size: {len(X_train)}")
print(f"Test set size: {len(X_test)}")
# สร้างโมเดล Naive Bayes
NB = GaussianNB()
# ฝึกโมเดลด้วยชุดข้อมูลฝึก
NB.fit(X_train, y_train)
# ตรวจสอบคลาสที่โมเดลเรียนรู้
print("Class labels:", NB.classes_)
# ค่าเฉลี่ยของแต่ละตัวทำนายในแต่ละคลาส
print("Mean of each feature per class:\n", NB.theta_)
# ค่าความแปรปรวนของแต่ละตัวทำนายในแต่ละคลาส
print("Variance of each feature per class:\n", NB.var_)
# ทำนายผลลัพธ์จากชุดทดสอบ
y_pred = NB.predict(X_test)
# คำนวณค��วามแม่นยำของโมเดล
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
# แสดง Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:\n", conf_matrix)
# รายงานผลการจำแนกประเภท
print("Classification Report:\n", classification_report(y_test, y_pred, target_names=['Down', 'Up']))
# แสดงความน่าจะเป็นที่ตัวอย่างในชุดทดสอบจะเป็น 'Up' หรือ 'Down'
probs = NB.predict_proba(X_test)
print("Predicted Probabilities (first 5 rows):\n", probs[:5])
คำอธิบาย code
GaussianNBใช้สำหรับ Naive Bayes Classifier แบบ Gaussian Distributiontrain_test_splitแบ่งข้อมูลเป็น ชุดฝึก (Train) และ ชุดทดสอบ (Test)accuracy_score,confusion_matrixและclassification_reportใช้วัดผลลัพธ์ของโมเดล- ตัวข้อมูล ใช้ ISLP โหลดชุดข้อมูล Smarket
Directionเป็นตัวแปรเป้าหมาย (Target Variable) ที่บอกว่า ตลาด�จะขึ้น (Up) หรือ ลง (Down)Lag1และLag2เป็นตัวแปรเชิงปริมาณที่ใช้เป็นตัวทำนาย- แบ่งข้อมูลเป็น 80% สำหรับฝึก และ 20% สำหรับทดสอบ
- ใช้คำสั่ง
NB.fit(X_train, y_train)ฝึกโมเดลด้วย ข้อมูลฝึกที่เตรียมไว้ - สุดท้ายผลลัพธ์ที่ได้จาก
GaussianNBNB.classes_→ แสดงคลาสที่โมเดลเรียนรู้ (Up,Down)NB.theta_→ แสดงค่าเฉลี่ยของ Lag1 และ Lag2 สำหรับแต่ละคลาสNB.var_→ แสดงค่าความแปรปรวนของ Lag1 และ Lag2 สำหรับแต่ละคลาสNB.predict(X_test)ใช้โมเดลที่ฝึกไว้เพื่อทำนาย Direction (Up/Down)
- ส่วนของการวัดผล
accuracy_score(y_test, y_pred)คำนวณ Accuracy ของโมเดลconfusion_matrix(y_test, y_pred)แสดง Confusion Matrixclassification_report(y_test, y_pred)แสดงค่า Precision, Recall และ F1-score
ผลลัพธ์ที่ได้
Year Lag1 Lag2 Lag3 Lag4 Lag5 Volume Today Direction
0 2001 0.381 -0.192 -2.624 -1.055 5.010 1.1913 0.959 Up
1 2001 0.959 0.381 -0.192 -2.624 -1.055 1.2965 1.032 Up
2 2001 1.032 0.959 0.381 -0.192 -2.624 1.4112 -0.623 Down
3 2001 -0.623 1.032 0.959 0.381 -0.192 1.2760 0.614 Up
4 2001 0.614 -0.623 1.032 0.959 0.381 1.2057 0.213 Up
Training set size: 1000
Test set size: 250
Class labels: [0 1]
Mean of each feature per class:
[[ 0.08348723 0.05406809]
[-0.02970943 -0.0178283 ]]
Variance of each feature per class:
[[1.32469991 1.23959474]
[1.15414993 1.24564215]]
Accuracy: 0.4640
Confusion Matrix:
[[ 19 113]
[ 21 97]]
Classification Report:
precision recall f1-score support
Down 0.47 0.14 0.22 132
Up 0.46 0.82 0.59 118
...
[0.47483613 0.52516387]
[0.69119749 0.30880251]
[0.4496747 0.5503253 ]
[0.57159402 0.42840598]]
จากผลลัพธ์นี้หมายความว่า
-
โมเดลสามารถทำนายได้ถูกต้อง 46.40% ของข้อมูลทดสอบทั้งหมด
-
จาก Confusion Matrix
[[TN=19 FP=113]
[FN=21 TP=97 ]]- True Negative (ทำนาย Down ถูก): 19 ครั้ง
- False Positive (ทำนาย Up ผิด จริงๆควรเป็น Down): 113 ครั้ง
- False Negative (ทำนาย Down ผิด จริงๆควรเป็น Up): 21 ครั้ง
- True Positive (ทำนาย Up ถูก): 97 ครั้ง
-
Classification Report
- สำหรับ class Down:
- Precision: 0.47 (47% ของการทำนายว่าเป็น Down ถูกต้อง)
- Recall: 0.14 (14% ของ Down ทั้งหมดถูกทำนายถูก)
- F1-score: 0.22 (ค่าเฉลี่ยระหว่าง Precision และ Recall)
- สำหรับ class Up:
- Precision: 0.46 (46% ของการทำนายว่าเป็น Up ถูกต้อง)
- Recall: 0.82 (82% ของ Up ทั้งหมดถูกทำนายถูก)
- F1-score: 0.59 (ค่าเฉลี่ยระหว่าง Precision และ Recall)
- สำหรับ class Down:
อธิบายเพิ่มเติมเรื่อง Confusion Matrix
Confusion Matrix เป็นเครื่องมือที่ใช้วัดประสิทธิภาพของโมเดล Machine Learning ในงาน Classification โดยแสดงการเปรียบเทียบระหว่างค่าที่ทำนายได้ (Predicted) กับค่าที่เป็นจริง (Actual)
ในกรณีของข้อมูลที่มี 2 classes (Binary Classification) คือ Up และ Down เมทริกซ์จะมีขนาด 2x2:
Predicted
Down Up
Actual Down 19 113
Up 21 97
แต่ละช่องในเมทริกซ์มีความหมายดังนี้:
- True Negative (TN) = 19 —> ค่าจริงเป็น Down และทำนายว่าเป็น Down (ทำนายถูก)
- False Positive (FP) = 113 —> ค่าจริงเป็น Down แต่ทำนายว่าเป็น Up (ทำนายผิด)
- False Negative (FN) = 21 —> ค่าจริงเป็น Up แต่ทำนายว่าเป็น Down (ทำนายผิด)
- True Positive (TP) = 97 —> ค่าจริงเป็น Up และทำนายว่าเป็น Up (ทำนายถูก)
จากเมทริกซ์นี้เราสามารถคำนวณค่าต่างๆ ได้เป็น
- Accuracy = (TN + TP) / (TN + FP + FN + TP) = (19 + 97) / (19 + 113 + 21 + 97) = 0.464 หรือ 46.4%
- Precision (ความแม่นยำ) = TP / (TP + FP)
- สำหรับ Up: 97 / (97 + 113) = 0.46 หรือ 46%
- Recall (ความครบถ้วน) = TP / (TP + FN)
- สำหรับ Up: 97 / (97 + 21) = 0.82 หรือ 82%
Confusion Matrix ช่วยให้เราเห็นว่าโมเดลทำผิดพลาดในลักษณะใด เช่น ในกรณีนี้โมเดลมีแนวโน้มที่จะทำนายผิดพลาดโดยทำนายว่าเป็น Up เมื่อค่าจริงเป็น Down (FP สูงถึง 113 ครั้ง) ซึ่งข้อมูลนี้มีประโยชน์ในการปรับปรุงโมเดลต่อไป