Clustering
Clustering คืออะไร
Clustering หรือการจัดกลุ่มข้อมูล เป็นเทคนิคใน สถิติและการเรียนรู้ของเครื่อง (Statistical Learning) ที่ใช้ในการ ค้นหากลุ่มย่อยหรือ Clusters ภายในชุดข้อมูล เป้าหมายคือ แบ่งข้อมูลออกเป็นกลุ่มที่แตกต่างกัน โดยให้ข้อมูลภายในกลุ่มเดียวกันมีความคล้ายคลึงกัน ในขณะที่ข้อมูลในกลุ่มต่างกันมีความแตกต่างกัน
ประเด็นสำคัญเกี่ยวกับ Clustering
- การเรียนรู้แบบไม่มีผู้สอน (Unsupervised Learning): Clustering ใช้ในกรณีที่ไม่มีตัวแปรเป้าหมายให้พยากรณ์ จุดประสงค์คือการค้นหาโครงสร้างภายในชุดข้อมูล
- การนำไปใช้งาน (Applications):
- การแบ่งกลุ่มตลาด (Market Segmentation): Clustering สามารถช่วยระบุกลุ่มลูกค้าที่มีแนวโน้มตอบสนองต่อโฆษณาเฉพาะทางหรือมีโอกาสซื้อสินค้า
- การวิเคราะห์ข้อมูล (Data Analysis): ใช้ค้นหากลุ่มย่อยในตัวอย่างมะเร็งเต้านมหรือกลุ่มของยีนเพื่อทำความเข้าใจโรคได้ดีขึ้น
- วิธีการ (Methods)
- K-means Clustering: เป็นวิธีที่พยายามแบ่งข้อมูลออกเป็นจำนวนกลุ่มที่กำหนดไว้ล่วงหน้า
- Hierarchical Clustering: ไม่จำเป็นต้องกำหนดจำนวนกลุ่มล่วงหน้า และให้ผลลัพธ์เป็นแผนภาพลำดับชั้น (Dendrogram) ที่แสดงความสัมพันธ์ของข้อมูล
- ข้อควรพิจารณา (Considerations)
- การจัดกลุ่มข้อมูลต้องตัดสินใจเกี่ยวกับประเด็นต่าง ๆ เช่น ควรมาตรฐานข้อมูลหรือไม่, ควรใช้มาตรวัดความแตกต่างแบบใด, และควรแบ่งข้อมูลออกเป็นกี่กลุ่ม
- จำเป็นต้องตรวจสอบว่ากลุ่มที่พบเป็นกลุ่มที่มีความหมายจริง หรือเป็นเพียงผลจากการกระจายตัวของข้อมูลแบบสุ่ม
- วิธีการ Clustering อาจไม่แข็งแกร่งพอต่อการเปลี่ยนแปลงของข้อมูลหรือค่าผิดปกติ (Outliers)
โดยสรุป Clustering เป็นเครื่องมือสำหรับการค้นหากลุ่มย่อยภายในชุดข้อมูล แต่ต้องใช้ความระมัดระวังในการพิจารณาปัจจัยต่าง ๆ และการตรวจสอบความถูกต้องของผลลัพธ์
มีวิธี Clustering หลายแบบ แต่สองวิธีที่เป็นที่รู้จักมากที่สุดคือ K-means Clustering และ Hierarchical Clustering
- K-Means Clustering: วิธีนี้แบ่งข้อมูลออกเป็น จำนวน cluster ที่กำหนดไว้ล่วงหน้า การใช้ K-means ต้องระบุจำนวน cluster ที่ต้องการ (K) จากนั้นอัลกอริทึมจะทำการจัดกลุ่มข้อมูลแต่ละจุดให้อยู่ในหนึ่งใน K cluster
- Hierarchical Clustering: วิธีนี้ ไม่ต้องกำหนดจำนวน cluster ล่วงหน้า แต่จะให้ผลลัพธ์เป็น โครงสร้างแบบต้นไม้ (Tree-based Representation) ที่เรียกว่า Dendrogram ซึ่งช่วยให้สามารถดูการจัดกลุ่มของข้อมูลในแต่ละระดับได้ วิธีที่พบได้บ่อยที่สุดของ Hierarchical Clustering คือ Bottom-up หรือ Agglomerative Clustering
เราจะมาเรียนรู้ผ่าน 2 วิธีนี้กัน
K-Means Clustering

ref: https://www.geeksforgeeks.org/k-means-clustering-introduction/
K-means Clustering เป็นวิธีการ เรียนรู้แบบไม่มีผู้สอน (Unsupervised Learning) ที่เรียบง่ายและมีประสิทธิภาพ โดยใช้ในการ แบ่งชุดข้อมูลออกเป็น K cluster ที่ไม่ทับซ้อนกัน ซึ่ง K เป็นจำนวนที่กำหนดล่วงหน้า เป้าหมายของ K-means Clustering คือการจัดกลุ่มข้อมูลให้ ความแปรปรวนภายใน cluster มีค่าน้อยที่สุด

ref: https://stanford.edu/~cpiech/cs221/handouts/kmeans.html
กระบวนการทำงานของ K-means Clustering
-
อัลกอริทึม (Algorithm):
- กำหนดหมายเลขเริ่มต้นให้กับข้อมูลแต่ละจุดแบบสุ่ม ตั้งแต่ 1 ถึง K ซึ่งจะเป็นการกำหนด cluster เริ่มต้น
- ทำซ้ำจนกว่าการจัดกลุ่มจะไม่เปลี่ยนแปลง:
- **(a) คำนวณจุดศูนย์กลาง (Centroid) ของแต่ละ cluster ** โดยค่า Centroid ของ cluster ที่ k คือเวกเตอร์ของค่าเฉลี่ยของแต่ละคุณลักษณะ (p features) สำหรับข้อมูลใน cluster นั้น
- (b) จัดกลุ่มใหม่ โดยให้แต่ละจุดอยู่ใน cluster ที่มี Centroid ใกล้ที่สุด โดยใช้ระยะทาง Euclidean Distance เป็นตัววัด
-
วัตถุประสงค์ (Objective): K-means Clustering พยายามลด ความแปรปรวนภายใน cluster ทั้งหมด ซึ่งคำนวณจากผลรวมของความแปรปรวนภายในแต่ละ cluster (W(Ck))
โดยที่ เป็นค่าที่วัดความแตกต่างของข้อมูลภายในแต่ละ cluster
-
Local Optima: เนื่องจากอัลกอริทึมของ K-means หาค่าที่เหมาะสมที่สุดใน�ระดับ จุดต่ำสุดเฉพาะที่ (Local Optimum) ไม่ใช่ จุดต่ำสุดทั่วโลก (Global Optimum) ผลลัพธ์จึงอาจขึ้นอยู่กับการกำหนดค่าเริ่มต้นแบบสุ่ม ดังนั้น ควรรันอัลกอริทึมหลายครั้งโดยใช้ค่าตั้งต้นที่แตกต่างกัน แล้วเลือกผลลัพธ์ที่ดีที่สุด
-
การเลือกค่า K: ต้องตัดสินใจว่าควรแบ่งข้อมูลออกเป็นกี่ cluster ซึ่งอาจใช้เทคนิค เช่น Elbow Method หรือ Silhouette Score ในการช่วยเลือกค่า K ที่เหมาะสม
ตัวอย่างปัญหา
สมมติว่ามีชุดข้อมูลที่มี 6 จุดข้อมูล และแต่ละจุดมี 2 คุณลักษณะ (features)
| Obs. | X1 | X2 |
|---|---|---|
| 1 | 1 | 4 |
| 2 | 1 | 3 |
| 3 | 0 | 4 |
| 4 | 4 | 1 |
| 5 | 6 | 2 |
| 6 | 4 | 0 |
ทำ K-means Clustering โดยกำหนด K = 2
ตัวอย่างโค้ด Python สำหรับ K-means Clustering
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# ข้อมูลตัวอย่าง
data = {'X1': [1, 1, 0, 4, 6, 4],
'X2': [4, 3, 4, 1, 2, 0]}
df = pd.DataFrame(data)
# มาตรฐานข้อมูล (Standardization)
scaler = StandardScaler()
scaled_df = scaler.fit_transform(df)
# ทำ K-means Clustering โดยกำหนด K = 2
kmeans = KMeans(n_clusters=2, n_init=20, random_state=42) # ตั้งค่า random_state เพื่อให้ผลลัพธ์สามารถทำซ้ำได้
kmeans.fit(scaled_df)
# ดึงผลลัพธ์การจัดกลุ่มและจุดศูนย์กลางของ cluster
cluster_labels = kmeans.labels_
centroids = kmeans.cluster_centers_
# แสดงผลลัพธ์แบบกราฟ
plt.figure(figsize=(8, 6))
plt.scatter(scaled_df[:, 0], scaled_df[:, 1], c=cluster_labels, cmap='viridis', marker='o', s=100)
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', marker='X', s=200, label='Centroids')
plt.title('K-Means Clustering Results (K=2)')
plt.xlabel('X1 (Scaled)')
plt.ylabel('X2 (Scaled)')
plt.legend()
plt.grid(True)
plt.show()
# แสดงผลลัพธ์การจัดกลุ่ม
print("Cluster Assignments:")
print(cluster_labels)
print("\\nCentroids:")
print(centroids)
คำอธิบายโค้ด:
- การปรับขนาดข้อมูล (Data Scaling): ใช้
StandardScalerเพื่อมาตรฐานข้อมูลก่อนทำ Clustering - การใช้งาน K-means: ใช้
KMeansจากsklearn.clusterโดยกำหนดn_init=20เพื่อรันอัลกอริทึม 20 ครั้งด้วยค่าเริ่มต้นที่แตกต่างกัน แล้วเลือกผลลัพธ์ที่ดีที่สุด - การดึงผลลัพธ์: สามารถดึง Cluster Assignments ได้จาก
labels_และจุดศูนย์กลางของแต่ละ cluster ได้จากcluster_centers_ - การวัดค่า Within-Cluster Variation: สามารถเข้าถึงค่าผลรวมของความแปรปรวนภายใน cluster (Sum of Squared Errors) ได้จาก
inertia_
ผลลัพธ์นั้น จาก code ให้ทำการการแสดงผลโดย ใช้ Matplotlib เพื่อแสดงผลลั�พธ์ของ Clustering ออกมา

จากรูป
- จุด X สีแดง แสดงถึง เซนทรอยด์ (ศูนย์กลางของแต่ละ cluster )
- จุดข้อมูลถูกระบายสีเป็น สองสี (ม่วงและเหลือง) เพื่อแสดงการแบ่งกลุ่ม
- Cluster 1 (จุดสีม่วง): อยู่บริเวณ มุมซ้ายบน ของกราฟ
- Cluster 2 (จุดสีเหลือง): อยู่บริเวณ มุมขวาล่าง ของกราฟ
- ตำแหน่งของเซนทรอยด์โดยประมาณ
- Centroid 1: ประมาณ (-1.0, 0.9)
- Centroid 2: ประมาณ (1.0, -0.9)
- ภาพการแสดงผลนี้แสดงให้เห็นว่า K-Means Algorithm สามารถระบุสองกลุ่มที่แตกต่างกันในข้อมูลได้อย่างแม่นยำ และค่า K = 2 เป็นตัวเลือกที่เหมาะสมสำหรับชุดข้อมูลนี้ เนื่องจากสามารถจับโครงสร้างของกลุ่มในข้อมูลได้ดี
สรุป
K-means Clustering เป็นวิธีที่มีประสิทธิภาพในการแบ่งกลุ่มข้อมูล แต่ต้องระวังข้อจำกัด เช่น การเลือกค่า K ที่เหมาะสม และผลลัพธ์ที่อาจได้รับผลกระทบจากค่าเริ่มต้นแบบสุ่ม การรันอัลกอริทึมหลายครั้งและใช้เทคนิคช่วยเลือก K สามารถช่วยให้ได้ผลลัพธ์ที่ดีขึ้น
Hierarchical Clustering

ref: https://www.geeksforgeeks.org/hierarchical-clustering/
Hierarchical Clustering เป็นวิธีจัดกลุ่มข้อมูลทางเลือกที่แตกต่างจาก K-means Clustering โดย ไม่จำเป็นต้องกำหนดจำนวน cluster ล่วงหน้า และให้ผลลัพธ์เป็น โครงสร้างต้นไม้ (Tree-like Representation) ที่เรียกว่า Dendrogram
Dendrogram คือ แผนภาพแบบต้นไม้ (tree-like diagram) ที่ใช้แสดงโครงสร้างของกลุ่ม clusters ในการจัดกลุ่มแบบลำดับชั้น (Hierarchical Clustering) อย่างเป็นภาพ
- Leaf (ใบ) แต่ละใบเริ่มต้นจากข้อมูลแต่ละจุดแยกกัน
- เมื่อไล่ขึ้นไปตาม ต้นไม้ (tree) ใบจะถูกรวมเข้ากับกิ่งตามระดับความคล้ายคลึงกัน
- ความสูงของการรวมกลุ่ม (height of the fusion) บ่งบอกถึงความแตกต่าง (dissimilarity) ของข้อมูล
- ถ้าการรวมกลุ่มเกิดที่ระดับต่ำ แสดงว่าข้อมูลมีความคล้ายกันสูง
- ถ้าการรวมกลุ่มเกิดที่ระดับสูง แสดงว่าข้อมูลมีความแตกต่างกันมากขึ้น
ประเด็นสำคัญเกี่ยวกับ Hierarchical Clustering
- Agglomerative Clustering (Bottom-up Approach):
- เริ่มต้นโดยให้ แต่ละข้อมูลเป็นกลุ่มของตัวเอง ซึ่งเรียกว่าแนวทางแบบ "bottom-up" เพราะเริ่มจากระดับล่างสุด (คล้ายกับใบของโครงสร้างต้นไม้) แล้วค่อย ๆ รวมกลุ่มขึ้นไป
- หลังจากนั้น อัลกอริทึมนี้จำเป็นต้องมี วิธีวัดความแตกต่าง (dissimilarity) หรือ ความคล้ายคลึงกัน (similarity) ระหว่างจุด��ข้อมูล และระหว่างกลุ่มของข้อมูลในภายหลัง โดย Euclidean distance เป็นวิธีที่นิยมใช้ แต่สามารถใช้มาตรการอื่นได้ตามลักษณะของข้อมูล
- การรวมกลุ่มแบบวนซ้ำ: อัลกอริทึมจะทำการ รวมกลุ่มที่ใกล้ที่สุด (มีความคล้ายคลึงกันมากที่สุด) แบบวนซ้ำ
- ในแต่ละขั้นตอน อัลกอริทึมจะ หากลุ่มที่คล้ายกันมากที่สุดสองกลุ่ม และรวมให้เป็น กลุ่มใหญ่ขึ้น
- กระบวนการนี้จะทำซ้ำไปเรื่อย ๆ จนกระทั่ง ข้อมูลทั้งหมดถูกรวมเป็นกลุ่มเดียว
- Linkage: ใช้ในการวัด Dissimilarity ระหว่าง cluster โดยมีหลายวิธีที่นิยมใช้:
- Complete Linkage: ใช้ค่าความแตกต่างมากที่สุดระหว่างสอง cluster (พิจารณาระยะทาง สูงสุด ระหว่างจุดในสองกลุ่ม ทำให้ได้กลุ่มที่กระชับกว่า)
- Single Linkage: ใช้ค่าความแตกต่างน้อยที่สุดระหว่างสอง cluster (มักสร้างกลุ่��มแบบ “chained clusters” ที่เกิดจากการเชื่อมต่อจุดใกล้กันทีละคู่)
- Average Linkage: ใช้ค่าเฉลี่ยของระยะทางระหว่างทุกจุดในสอง cluster
- Centroid Linkage: ใช้ระยะทางระหว่างจุดศูนย์กลางของแต่ละ cluster
- ref: https://www.youtube.com/watch?v=VMyXc3SiEqs
- มาตรการความแตกต่าง (Dissimilarity Measure): การเลือก มาตรการความแตกต่าง ที่เหมาะสมเป็นสิ่งสำคัญ หากใช้ Euclidean distance ซึ่งเป็นค่ามาตรฐาน ไม่สะท้อนความสัมพันธ์ของข้อมูลอย่างถูกต้อง อาจทำให้การรวมกลุ่มในขั้นแรก คลาดเคลื่อน การเลือกมาตรการอื่น เช่น Manhattan distance หรือ Correlation-based distance อาจทำให้การรวมกลุ่มเปลี่ยนแปลงได้
อัลกอริทึมของ Hierarchical Clustering
- เริ่มต้นด้วย n จุดข้อมูล และคำนวณค่าความแตกต่างของทุกคู่ของจุดข้อมูล (n choose 2 หรือ n(n-1)/2 คู่) โดยให้แต่ละจุดเป็น cluster ของตัวเอง
- สำหรับ i = n, n1, ..., 2:
- (a) ค้นหา cluster สองกลุ่มที่มีค่าความแตกต่างกันน้อยที่สุด แล้วรวมเข้าด้วยกัน
- (b) คำนวณค่าความแตกต่างใหม่ของ cluster ที่เหลือ i1 กลุ่ม
- ทำซ้ำขั้นตอนที่ (2) จนกว่าทุกจุดข้อมูลจะถูกรวมอยู่ใน cluster เดียว
ตัวอย่างปัญหา
ให้ชุดข้อมูล 4 จุด โดยแต่ละจุดมี 2 คุณลักษณะ (features):
| Obs. | X1 | X2 |
|---|---|---|
| 1 | 1 | 2 |
| 2 | 1 | 4 |
| 3 | 4 | 3 |
| 4 | 4 | 5 |
ทำ Hierarchical Clustering โดยใช้ Complete Linkage และ Euclidean Distance
ตัวอย่างโค้ด Python สำหรับ Hierarchical Clustering
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from scipy.cluster.hierarchy import dendrogram, linkage, cut_tree
# ข้อมูลตัวอย่าง
data = {'X1': [1, 1, 4, 4],
'X2': [2, 4, 3, 5]}
df = pd.DataFrame(data)
# มาตรฐานข้อมูล (Standardization)
scaler = StandardScaler()
scaled_df = scaler.fit_transform(df)
# ทำ Hierarchical Clustering โดยใช้ Complete Linkage
hc = AgglomerativeClustering(n_clusters=None,
distance_threshold=0,
linkage='complete')
hc.fit(scaled_df)
# คำนวณ Linkage Matrix สำหรับสร้าง Dendrogram
linked = linkage(scaled_df, method='complete')
# วาด Dendrogram
plt.figure(figsize=(10, 7))
dendrogram(linked,
orientation='top',
distance_sort='descending',
show_leaf_counts=True)
plt.title('Hierarchical Clustering Dendrogram (Complete Linkage)')
plt.xlabel('Sample Index')
plt.ylabel('Cluster Distance')
plt.show()
# ตัด Dendrogram เพื่อกำหนดกลุ่มข้อมูล
cluster_labels = cut_tree(linked, height=1.5).flatten()
print("Cluster labels:", cluster_labels)
คำอธิบาย code
- การปรับขนาดข้อมูล (Data Scaling): ใช้
StandardScalerเพื่อมาตรฐานข้อมูลก่อนทำ Clustering - AgglomerativeClustering: ใช้
AgglomerativeClusteringจากsklearn.clusterเพื่อทำ Hierarchical Clusteringlinkage='complete'กำหนดให้ใช้ Complete Linkagedistance_threshold=0และn_clusters=Noneใช้สำหรับคำนวณ Dendrogram ทั้งหมด
- การสร้าง Linkage Matrix: ใช้
linkageจากscipy.cluster.hierarchyเพื่อคำนวณค่าความแตกต่างระหว่าง cluster - การวาด Dendrogram: ใช้
dendrogramจากscipy.cluster.hierarchyเพื่อแสดงโครงสร้างการรวมกลุ่มของข้อมูล - การกำหนด cluster จากระยะห่าง (Cut Tree): ใช้
cut_treeเพื่อตัด Dendrogram ที่ระดับความสูงที่กำหนด (เช่น 1.5) และระบุ cluster ของแต่ละจุด
ผลลัพธ์
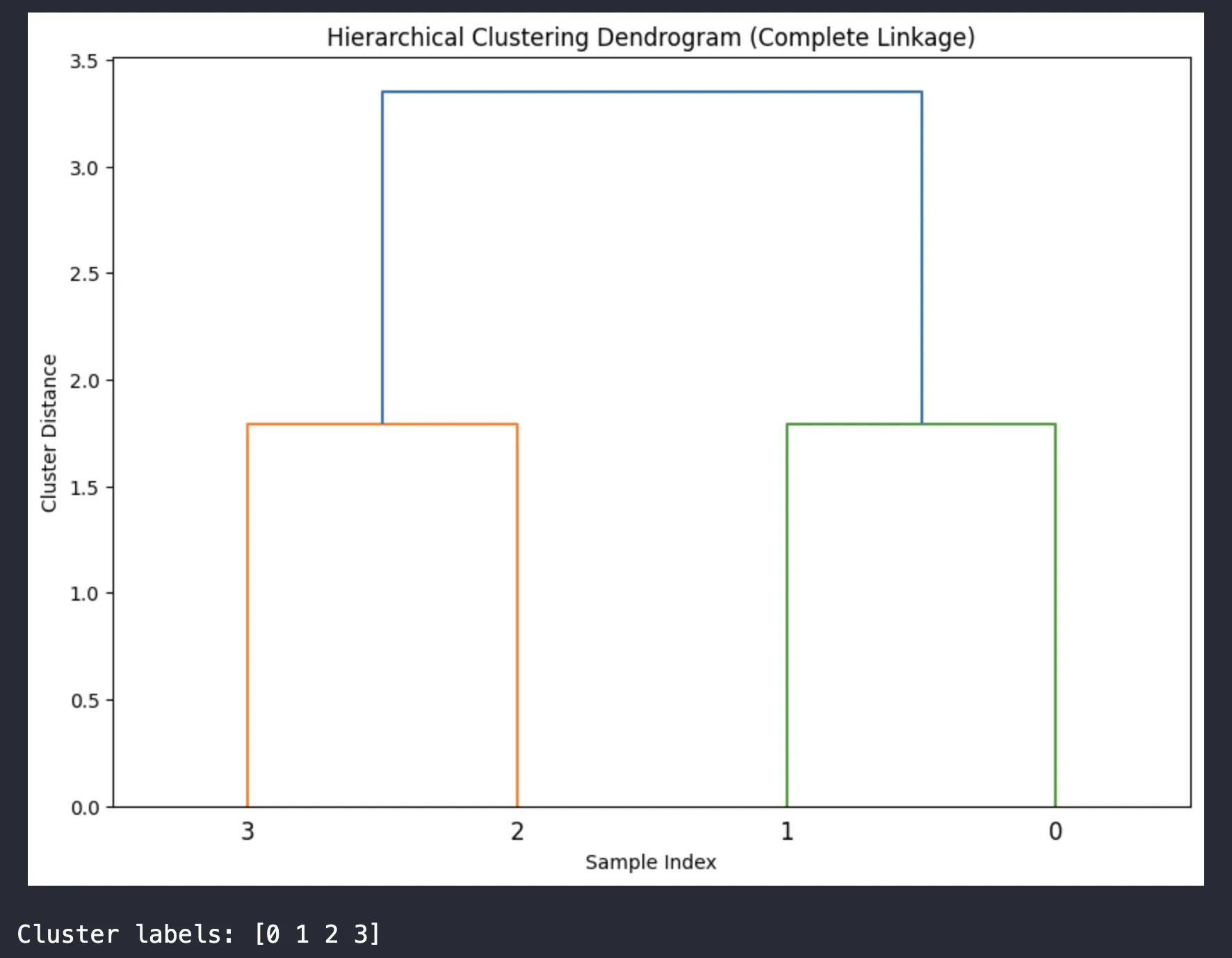
จากภาพ Dendrogram ที่ได้ แสดงผลการจัดกลุ่มข้อมูลแบบลำดับชั้น (Hierarchical Clustering) โดยใช้วิธี Complete Linkage สามารถตีความได้ดังนี้:
- แกนตั้ง (Cluster Distance) แสดงระยะห่างระหว่างกลุ่ม โดยยิ่งค่ามากแสดงว่ากลุ่มมีความแตกต่างกันมาก
- แกนนอน (Sample Index) แสดงดัชนีของข้อมูลตัวอย่าง (0, 1, 2, 3)
- การรวมกลุ่ม:
- ข้อมูลตัวอย่างที่ 0 และ 1 ถูกจัดอยู่ในกลุ่มเดียวกัน (เส้นสีเขียว)
- ข้อมูลตัวอย่างที่ 2 และ 3 ถูกจัดอยู่ในกลุ่มเดียวกัน (เส้นสีส้ม)
- สุดท้ายทั้งสองกลุ่มถูกรวมเข้าด้วยกันที่ระยะห่างประมาณ 3.3 (เส้นสีฟ้า)
- ผลการจัดกลุ่ม (Cluster labels: [0 1 2 3]):
- แต่ละตัวเลขแสดงกลุ่มที่ข้อมูลแต่ละตัวถูกจัดอยู่
- ในที่นี้ข้อมูลถูกแบ่งออกเป็น 4 กลุ่ม
จากการวิเคราะห์ Dendrogram นี้ แสดงให้เห็นว่าข้อมูลมีการจัดกลุ่มแบบลำดับชั้น โดยเริ่มจากการรวมข้อมูลที่มีความคล้ายคลึงกันเข้าด้วยกันก่อน (ระยะห่างน้อย) แล้วค่อยๆ รวมกลุ่มที่มีความแตกต่างกันมากขึ้นตามลำดับ จนกระทั่งรวมเป็นกลุ่มเดียวกันทั้งหมด
Hierarchical Clustering เป็นวิธีที่มีข้อดีตรงที่ ไม่ต้องกำหนดจำนวน cluster ล่วงหน้า และสามารถ แสดงโครงสร้างการรวมกลุ่มแบบลำดับขั้น ผ่าน Dendrogram อย่างไรก็ตาม ข้อเสียคือ ใช้ทรัพยากรมากกว่า K-means เนื่องจากต้องคำนวณค่าความแตกต่างของทุกคู่ของข้อมูล การเลือก Linkage Method ที่เหมาะสม และการกำหนดจุดตัดของ Dendrogram เป็นปัจจัยที่สำคัญต่อความถูกต้องของการจัดกลุ่ม