Resampling & Reduction
นอกเหนือจากการสร้างโมเดลแล้ว การทำความเข้าใจเกี่ยวกับการประเมินและปรับปรุงโมเดลเป็นสิ่งสำคัญ สองวิธีหลักในการประเมินโมเดล ได้แก่ Resampling และ Dimension Reduction
Resampling ใช้ในการประเมินประสิทธิภาพและความเสถียรของโมเดล โดยสร้างชุดข้อมูลหลายชุดจากข้อมูลต้นฉบับเพื่อประมาณค่าความแปรปรวน ประเมินข้อผิดพลาดในการทดสอบ และช่วยในการเลือกโมเดล
Dimension Reduction เป็นกระบวนการแปลงตัวแปรพยากรณ์เพื่อลดความซับซ้อนของโมเดล ซึ่งอาจช่วยเพิ่มความแม่นยำและทำให้โมเดลตีความได้ง่ายขึ้น
แม้ว่าวิธีทั้งสองจะมีบทบาทในการประเมินโมเดล แต่ Resampling มุ่งเน้นไปที่การวัดประสิทธิภาพของโมเดลโดยตรง ขณะที่ Dimension Reduction มุ่งเน้นไปที่การลดความซับซ้อนและการเลือกคุณลักษณะ (Feature Engineering) ซึ่งส่งผลต่อค่าประเมินโมเดลทางอ้อม
มาทำควา�มรู้จัก 2 Methods นี้กัน
Resampling Methods
วิธีการ Resampling เป็นกระบวนการสุ่มตัวอย่างจากชุดข้อมูลฝึกอบรมหลายครั้ง และปรับโมเดลใหม่ในแต่ละตัวอย่างเพื่อให้ได้ข้อมูลเพิ่มเติมเกี่ยวกับโมเดลที่ฟิตแล้ว
การใช้วิธี Resampling มีวัตถุประสงค์หลักดังนี้
- ประมาณค่าความแปรปรวนของการฟิตโมเดล เช่น ในการถดถอยเชิงเส้น (Linear Regression) การสุ่มตัวอย่างจากข้อมูลฝึกอบรมหลายครั้งและฟิตโมเดลถดถอยเชิงเส้นในแต่ละชุด สามารถช่วยให้เราวิเคราะห์ได้ว่าผลลัพธ์ที่ได้มีความแตกต่างกันมากน้อยเพียงใด
- ประมาณค่าความผิดพลาดของการทดสอบ (Test Error) สำหรับวิธีการเรียนรู้ทางสถิติเพื่อประเมินประสิทธิภาพของโมเดล
- การประเมินโมเดล (Model Assessment) โดยวัดผลการทำงานของโมเดล
- การเ�ลือกโมเดล (Model Selection) ซึ่งเป็นกระบวนการกำหนดระดับความยืดหยุ่นที่เหมาะสมของโมเดล
- ให้ค่าประมาณความแม่นยำของค่าพารามิเตอร์ หรือวิธีการเรียนรู้ทางสถิติที่กำหนด
วิธี Resampling ที่ใช้กันทั่วไป ได้แก่ Cross-validation และ Bootstrap
Cross-validation
Cross-validation เป็นเทคนิค Resampling ที่ใช้เพื่อ ประมาณค่าความผิดพลาดของการทดสอบ (Test Error Rate) สำหรับวิธีการเรียนรู้ทางสถิติ หรือเพื่อ เลือกระดับความยืดหยุ่นที่เหมาะสมของโมเดล กระบวนการนี้ทำโดยการแบ่งข้อมูลออกเป็นหลายชุดย่อย จากนั้นฝึกโมเดลโดยใช้บางชุด และทดสอบประสิทธิภาพของโมเดลกับชุดข้อมูลที่เหลือ โดย “Cross-Validation สามารถช่วยในการตัดสินใจได้ว่าตัวแปรเฉพาะนั้นเหมาะสมสำหรับการรวมไว้ในโมเดลหรือไม่ ?”
- Model Assessment (การประเมินโมเดล): Cross-Validation ช่วยในการประเมินว่า วิธีการเรียนรู้เชิงสถิติที่เลือกไว้จะมีประสิทธิภาพเพียงใดเมื่อใช้กับข้อมูลใหม่ที่เป็นอิสระจากชุดข้อมูลฝึก (Training Data)
- Model Selection (การเลือกโมเดล): Cross-Validation ถูกใช้เพื่อเลือกระดับความยืดหยุ่นที่เหมาะสมของโมเดล ซึ่งเรียกว่า Model Selection โดยสามารถนำไปใช้ได้ทั้งกับวิธีการเรียนรู้เชิงสถิติหลายวิธี หรือกับวิธีเดียวกันที่มีระดับความยืดหยุ่นต่างกัน เพื่อหาวิธีที่ให้ค่า Test Error ต่ำที่สุด
- Estimating Test Error (การประมาณค่าความผิดพลาดของการทดสอบ): Cross-Validation ให้วิธีการประมาณค่า Mean Squared Error (MSE) ของชุดข้อมูลทดสอบ โดยใช้ข้อมูลฝึก การประมาณค่านี้สะท้อนถึงความผิดพลาดเฉลี่ยเมื่อใช้วิธีการเรียนรู้เชิงสถิติในการทำนายค่าของข้อมูลใหม่ที่ไม่เคยใช้ในการฝึกโมเดล
- Avoiding Overfitting (การหลีกเลี่ยงปัญหา Overfitting): Cross-Validation ช่วยป้องกันการเกิด Overfitting ซึ่งเป็นปัญหาที่เกิดขึ้นเมื่อโมเดลเรียนรู้ข้อมูลฝึกได้ดีเกินไปจนไม่สามารถทำงานได้ดีบนข้อมูลใหม่ โดยการประเมินโมเดลบนชุดข้อมูลตรวจสอบ (Validation Sets) หลายชุด Cross-Validation จะให้ค่าประมาณของประสิทธิภาพที่น่าเชื่อถือมากขึ้นสำหรับข้อมูลที่ไม่เคยเห็นมาก่อน
- Subset Selection (การเลือกชุดย่อยของตัวแปร): Cross-Validation สามารถใช้ระหว่างกระบวนการ Subset Selection เพื่อประเมินโมเดลที่มีชุดของตัวแปรที่แตกต่างกัน โดยการเปรียบเทียบค่า Cross-Validation Error ของโมเดลที่มีและไม่มีตัวแปรเฉพาะ จะช่วยให้สามารถประเมินได้ว่าตัวแปรนั้นมีส่วนช่วยเพิ่มประสิทธิภาพการทำนายของโมเดลหรือไม่
ประเภทของ Cross-validation
- Validation Set Approach วิธีนี้แบ่งข้อมูลที่มีอยู่เป็นสองส่วนแบบสุ่ม ได้แก่ Training Set และ Validation Set จากนั้นฟิตโมเดลบน Training Set และใช้โม��เดลนั้นทำนายค่าตอบสนองของข้อมูลใน Validation Set จากนั้นคำนวณ Validation Set Error Rate เพื่อประมาณค่าความผิดพลาดของการทดสอบ
- ข้อพิจารณา
- Validation Error Rate อาจมีความแปรปรวนสูง เนื่องจากผลลัพธ์ขึ้นอยู่กับว่าข้อมูลใดถูกสุ่มเลือกให้เป็น Training Set และ Validation Set
- อาจทำให้เกิดการประมาณค่าความผิดพลาดของการทดสอบสูงกว่าความเป็นจริง เนื่องจากโมเดลถูกฝึกบนข้อมูลเพียงบางส่วนแทนที่จะใช้ข้อมูลทั้งหมด
- ข้อพิจารณา
- Leave-One-Out Cross-Validation (LOOCV) LOOCV ใช้ข้อมูลเพียง หนึ่งตัวอย่าง เป็น Validation Set ส่วนที่เหลือทั้งหมดเป็น Training Set จากนั้นฝึกโมเดลกับ Training Set และใช้โมเดลนั้นทำนายค่าของตัวอย่างที่ถูกกันออกไป ค่าความผิดพลาดของการทดสอบ (Mean Squared Error: MSE) คำนวณได้จาก
กระบวนการนี้ทำซ้ำ n ครั้ง โดยแต่ละครั้งใช้ตัวอย่างที่แตกต่างกันเป็น Validation Set แล้วคำนวณค่าเฉลี่ยของค่าความผิดพลาดทั้งหมดเพื่อประมาณค่าความผิดพลาดของการทดสอบ
- k-Fold Cross-Validation วิธีนี้แบ่งข้อมูลออกเป็น k กลุ่ม (Folds) ที่มีขนาดใกล้เคียงกัน จากนั้นใช้กลุ่มแรกเป็น Validation Set และใช้ข้อมูลที่เหลือเป็น Training Set คำนวณค่า Mean Squared Error (MSE) จากกลุ่มที่ถูกกันออกไป ทำซ้ำกระบวนการ k ครั้ง โดยใช้แต่ละกลุ่มเป็น Validation Set ครั้งละหนึ่งกลุ่ม แล้วเฉลี่ยค่าความผิดพลาดที่ได้ทั้งหมด
- �ข้อดี
- ลดความแปรปรวนของค่า Test Error ที่เกิดจากการสุ่มเลือก Training และ Validation Set
- มีความยืดหยุ่นมากกว่า Validation Set Approach
- ข้อได้เปรียบของ k-Fold CV เมื่อเทียบกับ LOOCV: เมื่อ k < n วิธีนี้ใช้เวลาคำนวณน้อยกว่า LOOCV เนื่องจากต้องฝึกโมเดลเพียง k ครั้ง แทนที่จะเป็น n ครั้ง
Step โดยประมาณของ Cross validation
ขั้นตอนทั่วไปสำหรับการทำ Cross-Validation มีดังนี้:
-
แบ่งข้อมูล (Divide the data): แบ่งชุดข้อมูลที่มีอยู่เป็น k กลุ่ม หรือ folds
- ในวิธี Validation Set Approach ข้อมูลจะถูกแบ่งเป็นชุดฝึก (Training Set) และชุดตรวจสอบ (Validation หรือ Hold-out Set) โดยโมเดลจะถูกฝึกด้วยชุดฝึกและประเมินผลด้วยชุดตรวจสอบ
- ในวิธี Leave-One-Out Cross-Validation (LOOCV) ใช้ข้อมูลเพียง 1 ตัวเป็นชุดตรวจสอบ และข้อมูลที่เหลือเป็นชุดฝึก โดยทำซ้ำ n ครั้ง (ตามจำนวนข้อมูลทั้งหมด)
- ในวิธี k-Fold Cross-Validation ข้อมูลจะถูกแบ่งเป็น k กลุ่มเท่า ๆ กัน หรือ k folds
-
วนซ้ำผ่านแต่ละ Fold (Iterate through the folds): สำหรับแต่ละ fold i
- ใช้ fold i เป็นชุดตรวจสอบ
- ฝึกโมเดลด้วยชุดข้อมูลที่เหลือ (k-1 folds)
- ทำนายผลลัพธ์สำหรับข้อมูลในชุดตรวจสอบ
- คำนวณค่า Mean Squared Error (MSE) ของ fold ที่ถูกกันไว้ สำหรับการจำแนกประเภท (Classification) ใช้จำนวนตัวอย่างที่ทำนายผิด
-
คำนวณค่า Cross-Validation Error (Calculate the cross-validation error): หาค่าเฉลี่ยของ Test Error จาก k รอบ โดยใช้สูตร:
- ในกรณีของการจำแนกประเภท ค่า LOOCV Error Rate จะอยู่ในรูปแบบ:
- การประเมินและเลือกโมเดล (Model assessment and selection): ใช้ผลลัพธ์จาก Cross-Validation เพื่อ:
- ประเมินประสิทธิภาพของวิธีการเรียนรู้เชิงสถิติที่กำหนด
- เปรียบเทียบโมเดลต่าง ๆ และเลือกโมเดลที่มีค่า Test Error โดยประมาณต่ำที่สุด
- เลือกระดับความยืดหยุ่นที่เหมาะสมของโมเดล
- เลือกค่าพารามิเตอร์ปรับแต่ง (Tuning Parameter) ที่เหมาะสม
ข้อสำคัญ: เมื่อใช้ Cross-Validation สำหรับการเลือกโมเดล จำเป็นต้องใช้เฉพาะชุดข้อมูลฝึก (Training Observations) ในแต่ละ Training Fold เพื่อให้ได้ค่าประมาณ Test Error ที่ถูกต้อง หากใช้ข้อมูลทั้งหมดในการเลือกโมเดลที่ดีที่สุดในแต่ละขั้นตอน ค่า Cross-Validation Error ที่ได้รับจะไม่แม่นยำ
ตัวอย่างการใช้ Cross-validation ใน Python
ตัวอย่างนี้ใช้ การทำ Cross Validation กับโมเดล sm.OLS โดยใช้ KFold จาก scikit-learn เพื่อแบ่งชุดข้อมูลเป็น 5 ส่วน แล้วฝึกโมเดลบนชุดฝึกและทดสอบบนชุดทดสอบในแต่ละรอบ พร้อมคำนวณค่า Mean Squared Error (MSE) ของแต่ละ fold และหาค่าเฉลี่ยของ MSE เพื่อประเมินประสิทธิภาพของโมเดลอย่างเป็นระบบและลดความเอนเอียงจากการแบ่งชุดข้อมูลเพียงครั้งเดียว
import numpy as np
import statsmodels.api as sm
from ISLP import load_data
from ISLP.models import sklearn_sm
from sklearn.model_selection import cross_val_score, KFold
# โหลดชุดข้อมูล Auto
Auto = load_data('Auto')
Y = Auto['mpg']
H = np.array(Auto['horsepower'])
# เพิ่มค่า Intercept สำหรับ OLS
X = sm.add_constant(H.reshape(-1, 1))
# ใช้ sklearn_sm() เป็น wrapper สำหรับโมเดล OLS
M = sklearn_sm(sm.OLS)
# กำหนด KFold สำหรับ Cross Validation
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# ทำ Cross Validation และคำนวณค่า R-squared (neg_mean_squared_error)
scores = cross_val_score(M, X, Y, cv=kf, scoring='neg_mean_squared_error')
# แสดงผลลัพธ์
print(f'Mean Squared Error (MSE) for each fold: {-scores}')
print(f'Average MSE: {-scores.mean()}')
คำอธิบายโค้ด
- โหลดไลบรารีที่จำเป็น เช่น
numpy,sklearnและstatsmodels - โหลดชุดข้อมูล
Auto - สร้าง Feature และ Target
Xคือค่า horsepower พร้อมกับ intercept (sm.add_constant)Yคือค่า mpg ที่เราต้องการทำนาย- ใช้
sklearn_sm(sm.OLS)เพื่อแปลงโมเดลstatsmodelsให้เข้ากับscikit-learnได้
- Cross Validation
- ใช้
KFoldแบ่งข้อมูลเป็น 5 ส่วน (5-fold cross-validation). scoring='neg_mean_squared_error'ใช้เพื่อประเมินความแม่นยำของโมเดล โดยให้ค่าเป็นค่าลบของ MSE- ใน
scikit-learnค่าที่ใช้ในcross_val_scoreหรือcross_validateต้องเป็น ค่าสูง=ดี เช่น ค่า Accuracy หรือ R-squared ที่สูงแสดงว่าโมเดลดี - แต่ MSE ยิ่ง ต่ำ=ดี ดังนั้นเพื่อให้เข้ากับระบบ scoring ของ
scikit-learnจึงแปลง MSE ให้เป็นค่าลบ โดยใช้neg_mean_squared_errorนั่นคือ การเอาค่าที่ได้มาทำการคูณด้วย -1 ให้กลายเป็นบวกนั่นเอง
- ใช้
ผลลัพธ์
Mean Squared Error (MSE) for each fold: [22.15323712 29.14787841 26.67385214 19.52413152 23.60002108]
Average MSE: 24.21982405486085
จากผลลัพธ์
- ค่า Mean Squared Error (MSE) สำหรับแต่ละ fold คือ
[22.15, 29.15, 26.67, 19.52, 23.60] - ค่า MSE ที่ต่ำแสดงถึงความคลาดเคลื่อนระหว่างค่าจริง (
Y) กับค่าที่โมเดลทำนายได้ที่น้อย - ในกรณีนี้ ค่า MSE มีความผันผวนในช่วงประมาณ 19 ถึง 29 ซึ่งอาจบ่งบอกถึงความไม่สม่ำเสมอของประสิทธิภาพโมเดลขึ้นอยู่กับการแบ่งชุดข้อมูล
- ค่าเฉลี่ย MSE อยู่ที่
24.22= โดยเฉลี่ยแล้ว โมเดลมีความคลาดเคลื่อนประมาณ 24.22 หน่วยจากค่าจริง - ประเมิน model
- ถ้าเป้าหมายคือการลดค่า MSE ให้ต่ำที่สุด ผลลัพธ์นี้อาจชี้ให้เห็นว่าโมเดลยังมีโอกาสในการปรับปรุง เช่น การเพิ่ม Feature, การทำ Polynomial Regression หรือการใช้โมเดลที่ซับซ้อนขึ้น
- ความผันผวนของ MSE ระหว่างแต่ละ fold อาจบ่งบอกถึงความไม่สมดุลของชุดข้อมูล หรือโมเดลอาจมีปัญหา Overfitting หรือ Underfitting ขึ้นอยู่กับลักษณะข้อมูล
Bootstrap
Bootstrap เป็นเทคนิค Resampling ที่ใช้เพื่อ ประเมินค่าความแปรปรวนของค่าพารามิเตอร์ หรือ วิธีการเรียนรู้ทางสถิติ โดยใช้การสุ่มตัวอย่างจากชุดข้อมูลต้นฉบับ แบบมีการคืนค่า (with replacement) เพื่อสร้างชุดข้อมูลใหม่หลายชุดที่เรียกว่า Bootstrap Data Sets
กระบวนการทำ Bootstrap
- Sampling:
- สร้าง B ชุดข้อมูล Bootstrap แต่ล��ะชุดมีขนาด n โดยสุ่มตัวอย่าง n จุดข้อมูลจากชุดข้อมูลต้นฉบับ แบบมีการคืนค่า
- บางข้อมูลอาจถูกสุ่มเลือกซ้ำหลายครั้ง ในขณะที่บางข้อมูลอาจไม่ได้ถูกเลือกเลย
- Model Fitting:
- ฟิตโมเดลสถิติที่ต้องการกับแต่ละ B ชุดข้อมูล Bootstrap และบันทึกค่าพารามิเตอร์ที่ได้จากแต่ละรอบ
- ตัวอย่างเช่น หากต้องการประมาณค่าความคลาดเคลื่อนของค่าสัมประสิทธิ์ใน Regression Model สามารถฟิตโมเดลบนแต่ละชุดข้อมูล Bootstrap และบันทึกค่าค่าสัมประสิทธิ์ที่ได้
- Estimation:
- คำนวณ ค่าเบี่ยงเบนมาตรฐานของค่าพารามิเตอร์ จาก B ชุดข้อมูล Bootstrap ซึ่งเป็นค่าประมาณความคลาดเคลื่อน (Standard Error: SE) ของค่าพารามิเตอร์ที่ประมาณจากชุดข้อมูลต้นฉบับ
ความแตกต่างระหว่าง Cross Validation กับ Bootstrap
- วัตถุประสงค์ (Purpose)
- Cross-validation ถูกใช้หลัก ๆ สำหรับ การประเมินและเลือกโมเดล (model assessment and selection) โดยมีเป้าหมายเพื่อประมาณค่าความคลาดเคลื่อนของการทดสอบ (test error) ที่เกี่ยวข้องกับวิธีการเรียนรู้ทางสถิติ เพื่อประเมินประสิทธิภาพและเลือกระดับความซับซ้อนของโมเดลที่เหมาะสม
- Bootstrap ถูกใช้เพื่อ หาความไม่แน่นอน (uncertainty) ที่เกี่ยวข้องกับตัวประมาณค่า (estimator) หรือวิธีการเรียนรู้ทางสถิติ โดยเป็นการวัดความแม่นยำของตัวประมาณ�ค่านั้น ๆ เช่น การใช้ Bootstrap เพื่อประมาณค่า Standard Error ของตัวค่าสัมประสิทธิ์ใน Linear Regression
- เทคนิคการสุ่มตัวอย่าง (Resampling Technique)
- Cross-validation ใช้วิธี แบ่งข้อมูล ออกเป็นหลายชุดย่อย (folds) โดยใช้บางชุดสำหรับฝึกโมเดล (training) และบางชุดสำหรับตรวจสอบความถูกต้อง (validation) ซึ่งโมเดลจะถูกฝึกหลายครั้ง โดยแต่ละครั้งจะใช้ชุดข้อมูลที่แตกต่างกันเป็นชุดตรวจสอบ
- Bootstrap ใช้วิธี สุ่มตัวอย่าง “ซ้ำ” แบบมีการคืนค่า (sampling with replacement) จากชุดข้อมูลเดิมหลายครั้ง เพื่อสร้างชุดข้อมูล Bootstrap หลายชุด จากนั้นจึงใช้วิธีการทางสถิติกับแต่ละชุดเพื่อสร้างการแจกแจงของค่าประมาณ (distribution of estimates)
- กรณีการใช้งาน (Use Cases):
- Cross-validation ถูกใช้สำหรับ ประมาณค่าความคลาดเคลื่อนของการทดสอบ (test error estimation), เปรียบเทียบโมเดลต่าง ๆ, และ ปรับพารามิเตอร์ของโมเ��ดล (model tuning) เพื่อให้ได้การทำนายที่แม่นยำและเชื่อถือได้มากขึ้นเมื่อใช้กับข้อมูลใหม่
- Bootstrap ถูกใช้ในกรณีที่ ไม่สามารถคำนวณ Standard Deviation ได้โดยตรง หรือมีความซับซ้อนในการคำนวณ และยังสามารถนำไปใช้กับวิธีการเรียนรู้ทางสถิติที่หลากหลาย รวมถึงใช้ในการประมาณค่า Standard Error ของสัมประสิทธิ์จากการทำ Linear Regression ด้วย
ตัวอย่างการใช้ Bootstrap ใน Python
ตัวอย่างนี้ เราสามารถใช้ Bootstrap สามารถใช้เพื่อประเมินความแปรปรวนของค่าสัมประสิทธิ์ของ Regression Model ได้ ตัวอย่างต่อไปนี้ใช้ Bootstrap เพื่อประมาณค่าความคลาดเคลื่อนของ Intercept และ Slope Coefficient ในการพยากรณ์ mpg โดยใช้ horsepower จากชุดข้อมูล Auto
import numpy as np
import statsmodels.api as sm
from ISLP import load_data
from functools import partial
# โหลดชุดข้อมูล Auto
Auto = load_data('Auto')
# ฟังก์ชัน Bootstrap สำหรับ Linear Regression
def boot_OLS(D, idx):
D_ = D.loc[idx]
Y_ = D_['mpg']
X_ = sm.add_constant(D_['horsepower'])
return sm.OLS(Y_, X_).fit().params
# ฟังก์ชันคำนวณ Bootstrap Standard Error
def boot_SE(func, D, n=None, B=1000, seed=10):
rng = np.random.default_rng(seed)
first_, second_ = 0, 0
n = n or D.shape[0]
for _ in range(B):
idx = rng.choice(D.index, n, replace=True)
value = func(D, idx)
first_ += value
second_ += value**2
return np.sqrt(second_ / B - (first_ / B)**2)
# คำนวณ Bootstrap Standard Errors สำหรับ Intercept และ Slope
hp_se = boot_SE(boot_OLS, Auto, B=1000, seed=10)
print(hp_se)
คำอธิบาย code
- โหลดชุดข้อมูล
Auto - กำหนดฟังก์ชัน
boot_OLS()- ใช้ข้อมูลที่สุ่มขึ้นใหม่ (
idx) - เพิ่มค่า Intercept ให้กับตัวแปร
horsepower - ฟิตโมเดล
OLSและดึงค่าค่าสัมประสิทธิ์
- ใช้ข้อมูลที่สุ่มขึ้นใหม่ (
- กำหนดฟังก์ชัน
boot_SE()เพื่อคำนวณ Bootstrap Standard Error - ใช้
boot_SE()คำนวณค่าความคลาดเคลื่อนของ Intercept และ Slope โดยใช้ B = 1000
ผลลัพธ์
const 0.731176
horsepower 0.006092
dtype: float64
นี่เป็นผลลัพธ์จากการวิเคราะห์ความสัมพันธ์ระหว่าง horsepower (แรงม้า) กับ mpg (ไมล์ต่อแกลลอน) ของรถยนต์จากชุดข้อมูล Auto โดย
- เมื่อรถยนต์มี horsepower เป็น 0 จะมีค่า mpg เท่ากั��บ 0.731176 ไมล์ต่อแกลลอน (ค่า constant)
- เมื่อ horsepower เพิ่มขึ้น 1 แรงม้า จะทำให้รถยนต์มีอัตราการใช้น้ำมัน (mpg) เพิ่มขึ้น 0.006092 ไมล์ต่อแกลลอน
ความสัมพันธ์นี้เป็นบวกแต่ค่อนข้างน้อย (0.006092) แสดงว่าการเพิ่มขึ้นของแรงม้ามีผลต่อการเพิ่มขึ้นของอัตราการใช้น้ำมันเพียงเล็กน้อยเท่านั้น
Dimension Reduction Methods
Dimension Reduction เป็นเทคนิคที่ใช้แปลงตัวแปรพยากรณ์ (Predictors) ให้เป็นเซตตัวแปรที่มีขนาดเล็กลง และใช้ตัวแปรเหล่านี้ในการฟิตโมเดลด้วยวิธี Least Squares วิธีนี้ช่วยลดความซับซ้อนของโมเดลโดยเปลี่ยนปัญหาการประมาณค่าสัมประสิทธิ์ p + 1 ตัว ให้เป็นปัญหาที่ง่ายขึ้นซึ่งต้องประมาณเพียง M + 1 ตัว โดยที่ M < p
กระบวนการทำ Dimension Reduction
- สร้างตัวแปรพยากรณ์ที่ถูกแปลงใหม่ (Z1, Z2, …, ZM) ซึ่งเป็น Linear Combinations ของตัวแปรพยากรณ์ต้นฉบับ p ตัว
- ฟิตโมเดลโดยใช้ตัวแปรใหม่ที่ได้ (M ตัว)
หากเลือกค่าคงที่ (Weights) สำหรับการสร้างตัวแปร M ตัว ได้อย่างเหมาะสม เทคนิค Dimension Reduction อาจให้ผลลัพธ์ที่ดีกว่าวิธี Least Squares Regression ทั่วไป
ข้อดีของ Dimension Reduction
- ช่วยควบคุม ความแปรปรวนของค่าประมาณค่าสัมประสิทธิ์
- ลดปัญหาการประมาณค่าสัมประสิทธิ์ที่ไม่แน่นอน โดยเฉพาะเมื่อ p มีค่ามากเมื่อเทียบกับ n
อย่างไรก็ตาม วิธีการลดมิติอาจทำให้เกิด Bias ในค่าประมาณค่าสัมประสิทธิ์ เนื่องจากมีข้อจำกัดในการใช้ข้อมูลต้นฉบับทั้งหมด แต่หากเลือกค่าของ M << p อย่างเหมาะสม วิธีนี้สามารถลด Variance ของค่าสัมประสิทธิ์ที่ได้จากการฟิตโมเดลได้อย่างมีประสิทธิภาพ
โดยวิธีการลดมิติที่สำคัญจะมี 2 วิธีนี้
- Principal Components Regression (PCR)
- Partial Least Squares (PLS)
Principal Components Regression (PCR)
Principal Components Regression (PCR) เป็นเทคนิค Dimension Reduction ที่ใช้สร้างตัวแปรใหม่ที่เรียกว่า Principal Components และใช้ตัวแปรเหล่านี้เป็น Predictors ในโมเดล Linear Regression ที่ฟิตด้วย Least Squares วิธีนี้สามารถนำมาใช้ในการพยากรณ์ค่าของตัวแปรตอบสนองที่สนใจได้
กระบวนการทำ PCR
- สร้างตัวแปรพยากรณ์ที่ถูกแปลงใหม่ (Z1, Z2, …, ZM) ซึ่งเป็น Principal Components
- ฟิตโมเดลโดยใช้ M Principal Components ที่ได้เป็นตัวพยากรณ์
แนวคิดหลักของ PCR
- มักพบว่ามีเพียง ไม่กี่ Principal Components ที่เพียงพอ ในการอธิบายความแปรปรวนของข้อมูลต้นฉบับ และความสัมพันธ์กับตัวแ�ปรตอบสนอง
- PCR ไม่ใช่วิธีการคัดเลือกตัวแปร (Feature Selection) เนื่องจาก Principal Components แต่ละตัวเป็น Linear Combination ของตัวแปรต้นฉบับทั้งหมด
ตัวอย่างการใช้ PCR ใน Python
ตัวอย่างนี้ใช้ PCA จาก sklearn.decomposition เพื่อพยากรณ์ Salary ในชุดข้อมูล Hitters
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import sklearn.linear_model as skl
import sklearn.model_selection as skm
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
from ISLP import load_data
# โหลดชุดข้อมูล Hitters
Hitters = load_data('Hitters')
Hitters = Hitters.dropna() # ลบ Missing Values
# กำหนดตัวแปรต้นและตัวแปรตอบสนอง
Y = np.array(Hitters['Salary'])
X = Hitters.drop(columns=['Salary'])
D = pd.get_dummies(X, drop_first=True) # แปลงตัวแปรหมวดหมู่เป็น Dummy Variables
# Standardize ข้อมูล
scaler = StandardScaler()
X = scaler.fit_transform(D)
# ตั้งค่า k-Fold Cross-Validation
kfold = skm.KFold(n_splits=10, shuffle=True, random_state=0)
# กำหนด PCA และ Linear Regression
pca = PCA()
linreg = skl.LinearRegression()
pipe = Pipeline([('pca', pca),
('linreg', linreg)])
# เลือกจำนวน Principal Components ที่เหมาะสมโดยใช้ Grid Search
param_grid = {'pca__n_components': range(1, 20)}
grid = skm.GridSearchCV(pipe,
param_grid,
cv=kfold,
scoring='neg_mean_squared_error')
grid.fit(X, Y)
# แสดงผล Cross-validated MSE ตามจำนวน Principal Components
n_comp = param_grid['pca__n_components']
plt.figure(figsize=(8, 8))
plt.errorbar(n_comp,
-grid.cv_results_['mean_test_score'],
grid.cv_results_['std_test_score'] / np.sqrt(kfold.n_splits))
plt.ylabel('Cross-validated MSE', fontsize=20)
plt.xlabel('# Principal Components', fontsize=20)
plt.xticks(n_comp[::2])
plt.show()
คำอธิบาย code
- โหลดชุดข้อมูล
Hittersและลบ Missing Values - กำหนดตัวแปรต้น (
X) และตัวแปรตอบสนอง (Y) - แปลงตัวแปรหมวดหมู่เป็น Dummy Variables
- Standardize ข้อมูลก่อนทำ PCA
- สร้าง Pipeline ที่ประกอบด้วย PCA และ Linear Regression
- ใช้ Grid Search เลือกจำนวน Principal Components ที่เหมาะสม
- ใช้ Cross-validation เพื่อคำนวณ MSE และพล็อตกราฟเปรียบเทียบผลลัพธ์
ผลลัพธ์
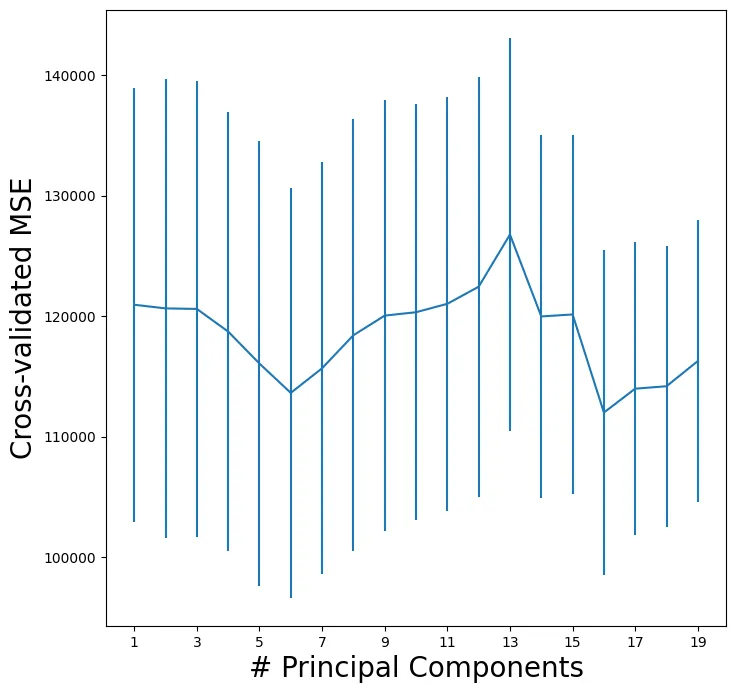
จากกราฟที่แสดงในภาพ เป็นการแสดงความสัมพันธ์ระหว่าง
- แกน X: จำนวน Principal Components (# Principal Components)
- แกน Y: ค่า Cross-validated MSE (Mean Squared Error)
- ขีดแนวตั้ง (vertical lines) หรือที่เรียกว่า error bars ในกราฟนี้แสดงถึงค่าความไม่แน่นอนหรือความแปรปรวน (variance) ของค่า MSE ที่ได้จากการทำ cross-validation
- ส่วนบนของเส้น: ค่า MSE สูงสุดที่เป็นไปได้
- ส่วนล่างของเส้น: ค่า MSE ต่ำสุดที่เป็นไปได้
- จุดตรงกลาง: ค่า MSE เฉลี่ย
- เส้นที่ยาว: แสดงว่ามีความแปรปรวนสูง (ผลลัพธ์ไม่คงที่ในแต่ละ fold ของ cross-validation)
- เส้นที่สั้น: แสดงว่ามีความแปรปรวนต่ำ (ผลลัพธ์ค่อนข้างคงที่ในแต่ละ fold)
การตีความผลลัพธ์
- กราฟแสดงให้เห็นว่าเมื่อใช้ Principal Components ประมาณ 7 components จะให้ค่า MSE ที่ต่ำที่สุด (ประมาณ 114,000)
- แนวโน้มของกราฟ:
- ช่วงแรก (1-7 components): ค่า MSE ลดลงเรื่อยๆ แสดงว่าการเพิ่ม components ช่วยให้โมเดลทำนายได้ดีขึ้น
- หลังจาก 7 components: ค่า MSE เริ่มสูงขึ้น แสดงถึงการเกิด overfitting ของโมเดล
- ค่า MSE ต่ำที่สุดอยู่ในช่วง 16-17 components โดยมีค่าประมาณ 113,000
- สามา��รถแบ่งได้เป็น
- ช่วงแรก (1-7): ค่า MSE ลดลงอย่างรวดเร็ว
- ช่วงกลาง (7-15): ค่า MSE มีความผันผวนและมีแนวโน้มเพิ่มขึ้นเล็กน้อย
- ช่วงท้าย (16-17): ค่า MSE ลดลงมาถึงจุดต่ำสุด
- หลังจาก 17 components: ค่า MSE เริ่มเพิ่มขึ้นอีกครั้ง
- แถบความคลาดเคลื่อน (error bars) ที่แสดงในแต่ละจุดบ่งบอกถึงความแปรปรวนของค่า MSE ในการ cross-validation
- ข้อสรุป:
- จำนวน Principal Components ที่เหมาะสมที่สุดคือประมาณ 7 components
- การใช้ components มากเกินไปไม่ได้ช่วยให้โมเดลดีขึ้น แต่กลับทำให้เกิด overfitting
- ควรเลือกใช้ 7 components เพื่อให้ได้ผลลัพธ์ที่ดีที่สุดในการทำนาย
- แต่ถ้าตามผลลัพธ์ 16-17 นั้นจะให้ค่า MSE น้อยที่สุด
- ดังนั้น หากต้องการเลือกจำนวน Principal Components ที่เหมาะสมที่สุด ควรเลือกใช้ 16-17 components เนื่องจากให้ค่า MSE ที่ต่ำที่สุด แต่ก็ต้องระวังว่าการใช้จำนวน components ที่มากอาจจะทำให้โมเดลซับซ้อนเกินไปได้
ค��ำถามต่อมา “จากหลักการนี้ เราจะรู้ได้อย่างไรว่าควรใช้ตัวแปรไหนบ้าง”
ในการเลือกว่าควรใช้ตัวแปรใดบ้างจาก Principal Components Analysis (PCA) เราสามารถพิจารณาได้จากหลายวิธี:
- Explained Variance Ratio
- ดูสัดส่วนความแปรปรวนที่แต่ละ PC อธิบายได้
- เลือก PC ที่สามารถอธิบายความแปรปรวนของข้อมูลได้มากที่สุด
- โดยทั่วไปมักเลือกให้ผลรวมของ variance ratio มีค่าประมาณ 80-90%
- Elbow Method
- ดูจากกราฟ scree plot ที่แสดงความสัมพันธ์ระหว่าง PC กับค่า eigenvalues หรือ explained variance
- เลือกจุดที่กราฟเริ่มมีความชันน้อยลงอย่างชัดเจน (จุดหักศอก)
- Cross-validation (ตามที่แสดงในกราฟ)
- ดูค่า MSE จากการ cross-validate
- เลือกจำนวน PC ที่ให้ค่า MSE ต่ำและเริ่มคงที่
- จากกราฟที่แสดง ประมาณ 11-13 components จะเหมาะสม เพราะหลังจากนั้น MSE แทบไม่ลดลงอีก
- Loading Scores
- ดู loading scores ของแต่ละตัวแปรใน PC ที่สำคัญ
- ตัวแปรที่มี loading scores สูงจะมีอิทธิพลต่อ PC นั้นๆ มาก
- ช่วยให้เราเข้าใจว่าตัวแปรใดมีความสำคัญต่อการอธิบายความแปรปรวนในข้อมูล
- Domain Knowledge
- นำความรู้เฉพาะทางมาประกอบการตัดสินใจ
- บางครั้งตัวแปรที่มีความสำคัญทางทฤษฎีอาจต้องถูกคงไว้ แม้จะมีค่า loading ไม่สูงมาก
ในทางปฏิบัติ มักใช้หลายวิธีร่วมกันเพื่อตัดสินใจ โดยพิจารณาทั้งด้านสถิติ (เช่น variance explained, MSE) และความเหมาะสมในการนำไปใช้งานจริง เพื่อให้ได้โมเดลที่มีประสิทธิภาพและใช้งานได้จริง
Partial Least Squares (PLS)
Partial Least Squares (PLS) เป็นเทคนิค Dimension Reduction และเป็นทางเลือกแบบมีการกำกับดูแล (Supervised) ของ Principal Components Regression (PCR)
PLS แตกต่างจาก PCR อย่างไร?
- PCR สร้าง Principal Components โดยพิจารณาควา��มแปรปรวนของตัวแปรต้นฉบับ (X1, X2, ..., Xp) แต่ไม่ได้ใช้ตัวแปรตอบสนอง (Y) ในการคำนวณ
- PLS คำนวณ Linear Combinations ของตัวแปรต้นฉบับ (X) โดยคำนึงถึง ความสัมพันธ์กับตัวแปรตอบสนอง (Y) ด้วย ทำให้ PLS สามารถเลือกทิศทางที่เหมาะสมที่สุดในการพยากรณ์ค่า Y
กระบวนการทำ PLS
- สร้างตัวแปรพยากรณ์ที่ถูกแปลงใหม่ (Z1, Z2, …, ZM) ซึ่งเป็น **Linear Combinations ของตัวแปรต้นฉบับ (X)
- ใช้ตัวแปรตอบสนอง (Y) เพื่อเลือกทิศทางของ Principal Components ที่มีความสัมพันธ์กับ Y มากที่สุด
- ฟิตโมเดลโดยใช้ M Principal Components ที่ได้
ตัวอย่างการใช้ PLS ใน Python
ตัวอย่างนี้ใช้ PLSRegression() จาก sklearn.cross_decomposition เพื่อพยากรณ์ Salary ในชุดข้อมูล Hitters
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn.model_selection as skm
from sklearn.preprocessing import StandardScaler
from sklearn.cross_decomposition import PLSRegression
from ISLP import load_data
# โหลดชุดข้อมูล Hitters
Hitters = load_data('Hitters')
Hitters = Hitters.dropna() # ลบ Missing Values
# กำหนดตัวแปรต้นและตัวแปรตอบสนอง
Y = np.array(Hitters['Salary'])
X = Hitters.drop(columns=['Salary'])
D = pd.get_dummies(X, drop_first=True) # แปลงตัวแปรหมวดหมู่เป็น Dummy Variables
# Standardize ข้อมูล
scaler = StandardScaler()
X = scaler.fit_transform(D)
# ตั้งค่า k-Fold Cross-Validation
kfold = skm.KFold(n_splits=10, shuffle=True, random_state=0)
# กำหนด PLS Regression
pls = PLSRegression(scale=True)
# เลือกจำนวน Principal Components ที่เหมาะสมโดยใช้ Grid Search
param_grid = {'n_components': range(1, 20)}
grid = skm.GridSearchCV(pls,
param_grid,
cv=kfold,
scoring='neg_mean_squared_error')
grid.fit(X, Y)
# แสดงผล Cross-validated MSE ตามจำนวน Principal Components
n_comp = param_grid['n_components']
plt.figure(figsize=(8, 8))
plt.errorbar(n_comp,
-grid.cv_results_['mean_test_score'],
grid.cv_results_['std_test_score'] / np.sqrt(kfold.n_splits))
plt.ylabel('Cross-validated MSE', fontsize=20)
plt.xlabel('# Principal Components', fontsize=20)
plt.xticks(n_comp[::2])
plt.show()
คำอธิบาย code
- โหลดชุดข้อมูล
Hittersและลบ Missing Values - กำหนดตัวแปรต้น (
X) และตัวแปรตอบสนอง (Y) - แปลงตัวแปรหมวดหมู่เป็น Dummy Variables
- Standardize ข้อมูลก่อนทำ PLS
- ใช้
PLSRegression(scale=True)ฟิตโมเดล - ใช้ Grid Search เลือกจำนวน Principal Components ที่เหมาะสม
- ใช้ Cross-validation เพื่อคำนวณ MSE และพล็อตกราฟเปรียบเทียบผลลัพธ์
ผลลัพธ์
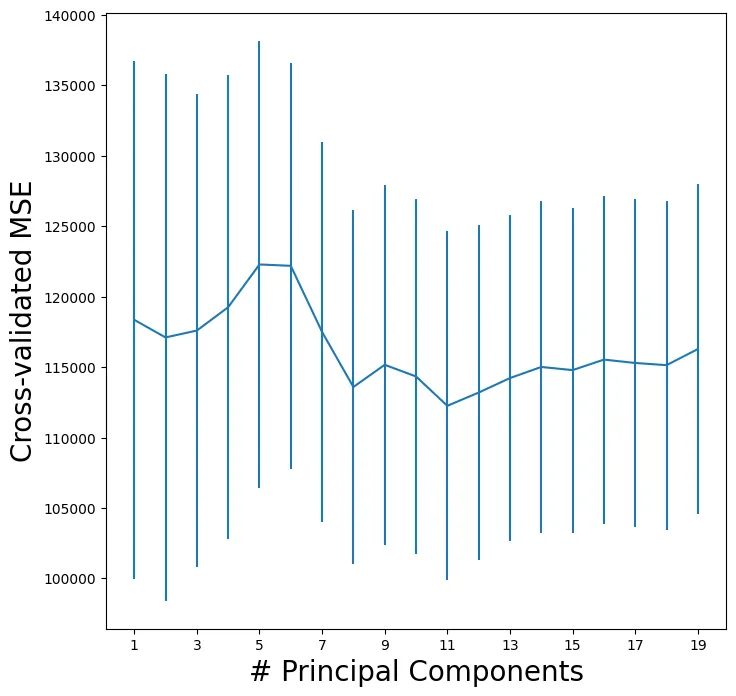
กราฟนี้แสดงความสัมพันธ์ระหว่าง จำนวน Principal Components (PCs) กับ ค่าความผิด��พลาดเฉลี่ยกำลังสองแบบ Cross-validation (MSE)
แกนของกราฟ
- แกน X: จำนวน Principal Components ที่ใช้ (ตั้งแต่ 1 ถึง 19)
- แกน Y: ค่า Cross-validated MSE (อยู่ในช่วงประมาณ 100,000 - 140,000)
- เส้นสีน้ำเงิน: ค่าความผิดพลาดเฉลี่ย (Mean MSE) ที่ได้จาก Cross-validation
- แท่งสีฟ้าแนวตั้ง: แสดงค่าความแปรปรวนของ MSE ในแต่ละจำนวน PCs
การสังเกตแนวโน้มสำคัญในกราฟ
- แนวโน้มเริ่มต้น (1-5 PCs):
- ค่าความผิดพลาดเริ่มต้นค่อนข้างสูง
- การใช้ PCs น้อยเกินไป ทำให้โมเดลจับข้อมูลได้ไม่เพียงพอ ส่งผลให้เกิด Underfitting
- มีแนวโน้มเพิ่มขึ้นเล็กน้อยจนถึง 5-6 PCs
- จุดสูงสุด (Peak) ที่ 5-6 PCs:
- ค่า MSE สูงสุด แสดงให้เห็นว่าโมเดลที่ใช้ 5-6 PCs อาจไม่เหมาะสมที่สุด
- เป็นไปได้ว่าโมเดลยังไม่สามารถสรุปโครงสร้างของข้อมูลได้ดีพอ
- แนวโ��น้มดีขึ้น (7+ PCs):
- หลังจาก 7 PCs ค่า MSE ลดลงอย่างชัดเจน
- หมายความว่าโมเดลสามารถจับข้อมูลได้ดีขึ้นเมื่อเพิ่ม PCs
- การทรงตัวของโมเดล (11+ PCs):
- ตั้งแต่ PC 11 เป็นต้นไป ค่า MSE ค่อนข้างคงที่
- แสดงว่า เพิ่ม PCs มากขึ้นแล้วไม่ได้ช่วยลดความผิดพลาดอย่างมีนัยสำคัญ
ดังนั้น
- ใช้ PCs น้อยเกินไป (1-5 PCs) ทำให้สูญเสียข้อมูลที่จำเป็น และโมเดลอาจมีความผิดพลาดสูง
- หลังจาก 7 PCs โมเดลเริ่มมีประสิทธิภาพดีขึ้น และความผิดพลาดลดลง
- ตั้งแต่ 11-13 PCs เป็นต้นไป การเพิ่ม PCs ไม่ได้ให้ประโยชน์ที่ชัดเจน
- จำนวน PCs ที่เหมาะสมที่สุด ดูเหมือนจะอยู่ที่ 11-13 PCs ซึ่งให้ประสิทธิภาพที่ดี โดยไม่เพิ่มความซับซ้อนของโมเดลโดยไม่จำเป็น
Mean Squared Error (MSE) for each fold: [22.15323712 29.14787841 26.67385214 19.52413152 23.60002108] Average MSE: 24.21982405486085