Hash Table
Hash Table คืออะไร
Hash Table คือโครงสร้างข้อมูลชนิดหนึ่งที่ใช้สำหรับการจัดเก็บข้อมูลแบบคู่ key-value เอาไว้ โดย หลักการทำงานของ Hash Table คือ
- มี Hash Function ที่ใช้ในการแปลง key ให้เป็นค่า index ของ Hash Table
- ค่า index ที่ได้จาก Hash Function จะใช้เป็นตำแหน่งในการจัดเก็บ value ที่ตรงกับ key นั้นใน Hash Table ได้
โดย Hash function คือ function ที่ใช้ในการแปลงข้อมูล input ให้เป็น index หรือ key สำหรับการจัดเก็บและค้นหาข้อมูลในโครงสร้างข้อมูลแบบ Hash Table
จาก Diagram เมื่อมี นำเข้าข้อมูล Input Data ตัว Hash Function จะทำการแปลงข้อมูลนั้นให้เป็นค่า Hash Value ซึ่งจะถูกนำไปใช้เป็น index ในการจัดเก็บและค้นหา Value ใน Hash Table โดยค่าที่ได้จะถูกจัดเก็บใน Bucket/Slot ที่ตรงกับ index นั้นๆ ไว้ (เหมือนๆกับ Array แต่มีคนคำนวน index ออ�กมาให้)
ส่งผลทำให้ การเข้าถึงข้อมูลใน Hash Table จะใช้เวลาดีหรือไม่ดี ในการค้นหา แทรก และลบข้อมูล ก็จะขึ้นอยู่กับ Hash function ด้วยเช่นกัน
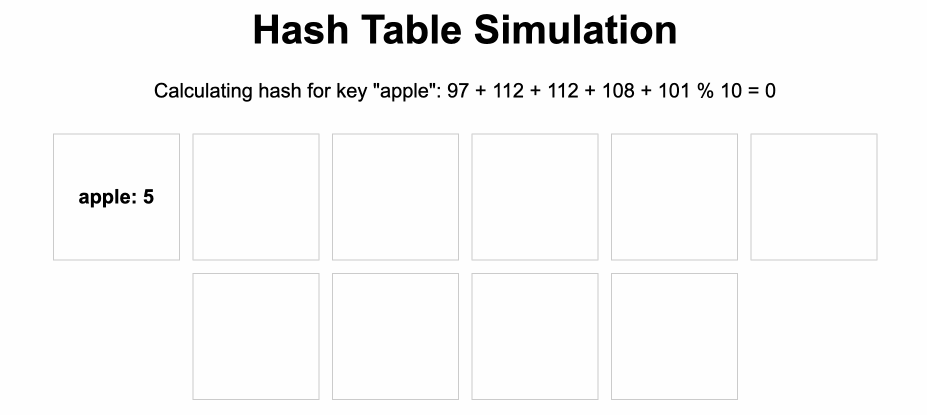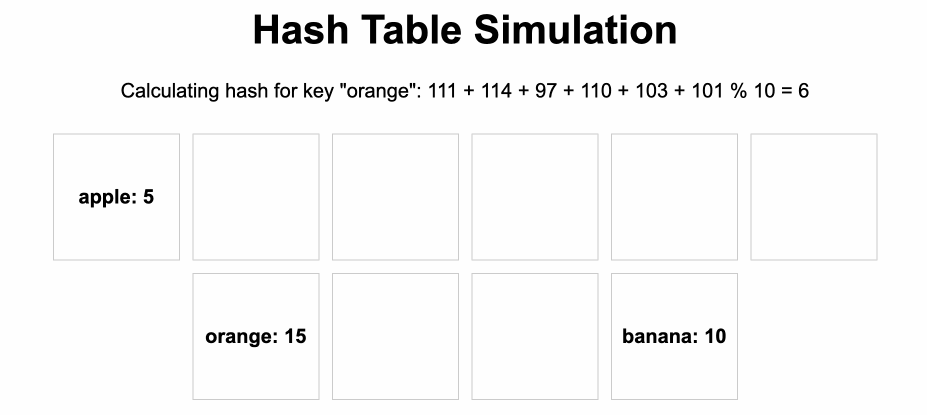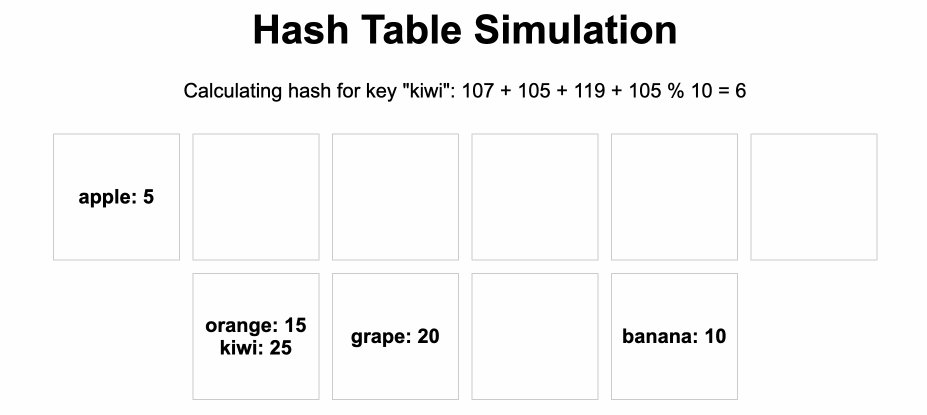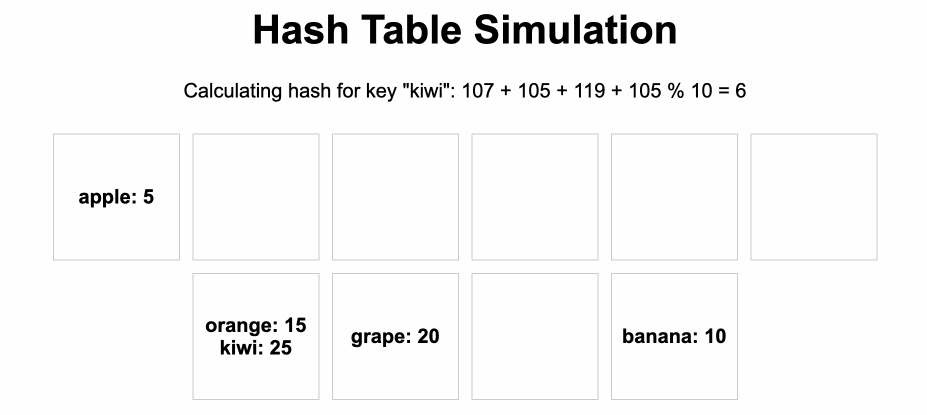
เช่นตัวอย่าง ตาม Animation นี้ที่เราจะสร้าง Array สำหรับเก็บ key - value ไว้โดย
- ให้ key ที่เก็บเป็น string และ value เป็นตัวเลข
- ทุกครั้งที่จะนำข้อมูลเข้า hash table เราก็จะคำนวน string ออกมาเป็นตัวเลขค่าหนึ่ง โดยใช้ hash function (เช่น graph = 7, kiwi = 6) จากนั้นก็นำเลขที่ได้หลังจากคำนวน hash function ไปใช้เป็น index สำหรับจัดเก็บค่าใน Array ได้
ข้อดีและข้อเสียของ Hash Table
ข้อดี
- การค้นหา แทรก และลบข้อมูลเร็ว เหมาะสำหรับการจัดเก็บข้อมูลขนาดใหญ่ที่ต้องการค้นหาข้อมูลอย่างรวดเร็ว (หาก hash function มีการกระจายตัวของ index อย่างถูกต้อง)
ข้อเสีย
- การเลือก hash function ที่ไม่ดีอาจทำให้เกิดการกระจุกต��ัว (clustering) ของข้อมูล ส่งผลให้ประสิทธิภาพในการค้นหาลดลงได้
- อาจเกิดการชนกันของค่า index ที่ได้จาก hash function (ต้องมีวิธีการจัดการกับการชนกันนี้)
- การลบข้อมูลอาจทำให้เกิดช่องว่างใน Hash table ออกมาได้ (ต้องมีวิธีการจัดการกับช่องว่างเหล่านี้เช่นกัน)
นี่คือตัวอย่าง code c++
#include <iostream>
#include <string>
#include <vector>
using namespace std;
// Define the hash table entry structure
struct HashEntry {
string key;
int value;
HashEntry() : key(""), value(-1) {}
HashEntry(string k, int v) : key(k), value(v) {}
};
class HashTable {
private:
// Vector to store the hash table entries
vector<HashEntry> table;
int capacity; // Total capacity of the hash table
// Hash function to map keys to indices
int hashFunction(string key) {
int hash = 0;
for (char c : key) {
hash =
(hash * 31 + c) % capacity; // Use a simple polynomial hash function
}
return hash;
}
public:
HashTable(int cap) : capacity(cap), table(cap) {}
// Insert a key-value pair into the hash table
void insert(string key, int value) {
int index = hashFunction(key);
table[index] = HashEntry(key, value);
}
// Search for a key in the hash table
int search(string key) {
int index = hashFunction(key);
if (table[index].key == key) {
return table[index].value;
}
return -1; // Key not found
}
// Remove a key-value pair from the hash table
void remove(string key) {
int index = hashFunction(key);
if (table[index].key == key) {
table[index] = HashEntry("", -1); // Mark as deleted
}
}
};
int main() {
HashTable ht(10); // Create a hash table with capacity 10
// Insert some key-value pairs
ht.insert("apple", 5);
ht.insert("banana", 10);
ht.insert("orange", 15);
// Search for a key
cout << "Value of 'banana': " << ht.search("banana")
<< endl; // Output: Value of 'banana': 10
// Remove a key
ht.remove("apple");
// Search for the removed key
cout << "Value of 'apple': " << ht.search("apple")
<< endl; // Output: Value of 'apple': -1
return 0;
}
จาก code แสดงตัวอย่างของการใช้งาน HashTable
เริ่มต้นจาก HashTable
- มี class
HashTableแทนโครงสร้างข้อมูลแบบ Hash Table ขึ้นมา - มี
HashEntryโครงสร้างข้อมูลสำหรับเก็บ key-value ไว้ - มี table ที่ใช้ vector สำหรับเก็บรายการข้อมูล (hash entry) ภายใน Hash Table
- มี capacity กำหนดขนาดของ Hash Table
- และสุดท้าย มี function ของ Hash table สำหรับ
- เพิ่มข้อมูล (
insertion) - ค้นหาข้อมูล (
search) - ลบข้อมูล (
removal)
- เพิ่มข้อมูล (
รวมถึงภายใน HashTable นั้นมีการเก็บ HashFunction สำหรับการเข้า hash key แล้วเช่นกัน
hashFunctionเป็น function private ภายใน classHashTable- หน้าที่หลักๆคือ รับค่า key (แบบ string) และส่งคืนค่า index แบบเลขจำนวนเต็ม ออกไป โดยมีวัตถุประสงค์ เพื่อ แปลงค่า key ไปเป็น index ที่เหมาะสม ที่จะใช้ภายใน Hash Table
- หลักการทำงาน
- วน loop ไปทีละตัวอักษรใน key
- นำค่า hash ปัจจุบันไปคูณ 31 แล้ว บวกด้วยค่า ASCII ของตัวอักษรนั้น
- นำผลลัพธ์ที่ได้ ไปหาผลหาร (modulo) ด้วย capacity เพื่อให้ได้ค่า index ที่อยู่ภายใน range ของ array ที่ถูกต้องออกมาได้
และสุดท้าย เมื่อเรียกใช้งานใน main ตัว code ก็จะมีตัวอย่าง
- สร้าง object HashTable ที่มีขนาด 10 ขึ้นมา
- เพิ่ม key-value โดยใช้ function
insert - ค้นหา key โดยใช้
searchและพิมพ์ค่า key ที่ต้องการดึงออกมา - ลบ key โดยใช้
remove - ตัวอย่างสุดท้าย เมื่อลอง ค้นหา key ที่ถูกลบไปแล้วอีกครั้ง จะแสดงผลลัพธ์ -1 กรณีที่ไม่พบข้อมูลที่ค้นหาออกมา
ผลลัพธ์
Value of 'banana': 10
Value of 'apple': -1
Hash Table กับ STL
สำหรับ Hash Table ใน C++ STL มีอยู่ 2 ตัวหลักๆ คือ
std::unordered_mapเป็น associative container ที่เก็บข้อมูลในรูปแบบ key-value โดยใช้ Hash Table ในการจัดเก็บภายใน ทำให้การค้นหา, แทรก และลบข้อมูลมีความเร็วเฉลี่ยเป็น O(1)std::unordered_setเป็น associative container ที่เก็บข้อมูลแบบ unique keys (key ไม่ซ้ำกัน) โดยใช้ Hash Table ในการจัดเก็บภายใน มีความเร็วในการค้นหา, แทรก และลบข้อมูลเฉลี่ยเป็น O(1) เช่นกัน แต่จะไม่มีส่วนของ mapped values เหมือน unordered_map
นี่คือตัวอย่างของการใช้ std::unordered_map
#include <iostream>
#include <string>
#include <unordered_map>
int main() {
// Create an unordered_map with string keys and int mapped values
std::unordered_map<std::string, int> umap = {
{"apple", 5}, {"banana", 10}, {"orange", 3}};
// Access and modify mapped values using [] operator
umap["apple"] = 7;
umap["kiwi"] = 2; // inserts new key-value pair
// Access mapped value using at() method
std::cout << "Number of bananas: " << umap.at("banana") << std::endl;
// Iterate over all key-value pairs
for (const auto &pair : umap) {
std::string key = pair.first;
int value = pair.second;
std::cout << key << ": " << value << std::endl;
}
return 0;
}
ผลลัพธ์
Number of bananas: 10
kiwi: 2
orange: 3
banana: 10
apple: 7
จะเห็นว่าการใช้งานก็เหมือนกันกับ Hash Table ที่เราสร้างเลย ในการใช้งานหรือการฝึก Problem Solving นั้น เราสามารถเลือกใช้ STL ตัวนี้พิจารณาในการทำ Hash Table ได้
และเทียบกันกับ std::unordered_set ด้วยตัวอย่างเดียวกัน
#include <iostream>
#include <string>
#include <unordered_set>
int main() {
// Create an unordered_set with string elements
std::unordered_set<std::string> uset = {"apple", "banana", "orange"};
// Insert elements into the unordered_set
uset.insert("kiwi");
uset.insert("apple"); // duplicate, won't be inserted
// Check if an element exists
if (uset.find("banana") != uset.end()) {
std::cout << "Found banana in the set" << std::endl;
}
// Iterate over all elements
for (const auto &elem : uset) {
std::cout << elem << std::endl;
}
return 0;
}
ผล�ลัพธ์
Found banana in the set
kiwi
orange
banana
apple
จะสังเกตกว่า ความแตกต่างระหว่าง unordered_set และ unordered_map คือ
- Elements
unordered_setประกอบด้วย elements (key) ที่ไม่ซ้ำกันเท่านั้นunordered_mapประกอบด้วย key-value pairs โดยแต่ละ key จะไม่ซ้ำกัน และมีค่าที่เก็บคู่กับ key นั้นอยู่ (mapped value)
- ก�ารเข้าถึงข้อมูล
unordered_set- สามารถตรวจสอบ เฉพาะ ว่ามี key (ข้อมูล) อยู่ภายในชุดข้อมูลหรือไม่ โดยใช้
find()หรือcount() - ไม่สามารถเข้าถึงหรือแก้ไขข้อมูลภายในชุดข้อมูลโดยตรง
- สามารถตรวจสอบ เฉพาะ ว่ามี key (ข้อมูล) อยู่ภายในชุดข้อมูลหรือไม่ โดยใช้
unordered_map- สามารถเข้าถึงและแก้ไข ค่าที่เกี่ยวข้อง (mapped value) ได้โดยใช้เครื่องหมาย
[]หรือ methodat()ได้
- สามารถเข้าถึงและแก้ไข ค่าที่เกี่ยวข้อง (mapped value) ได้โดยใช้เครื่องหมาย
- Duplicates
unordered_setไม่อนุญาต ให้มีข้อมูล (key) ที่ซ้ำกันได้ โดยการใส่ข้อมูลที่ซ้ำกันจะไม่มีผลใดๆกับ set ข้อมูลนี้unordered_mapไม่อนุญาต ให้มี key ที่ซ้ำกัน แต่จะ อนุญาต ให้ค่าที่เกี่ยวข้อง (mapped value) มีค่าที่ซ้ำกันได้ (value เหมือนกันใน key ที่ไม่เหมือนกันได้)
- Iteration
unordered_setเมื่อวน loop จะได้ เฉพาะ key (ข้อมูล) ภายในชุดข้อมูลunordered_mapเมื่อวน loop จะได้ key-value pairs ที่ต้องใช้firstและsecondเพื่อเข้าถึง key และ value ของตัวนั้นๆ
สรุปแล้ว ให้เลือกใช้
unordered_setกรณีที่ต้องการ เก็บข้อมูล (key) ที่ไม่ซ้ำกัน และต้องการ ตรวจสอบ ว่ามีข้อมูล (key) นั้นอยู่ภายในชุดข้อมูลหรือไม่unordered_mapกรณีที่ต้องการ จับคู่ข้อมูล (key-value pairs) โดยแต่ละ key จะ ไม่ซ้ำกันและต้องการ เข้าถึง หรือ แก้ไข ค่าที่เกี่ยวข้อง (mapped value) กับ key นั้นได้
ทั้ง unordered_set และ unordered_map ต่างก็ใช้ hash table ภายใน ทำให้มีความเร็วเฉลี่ยในการค้นหา, การเพิ่ม และการลบข้อมูลที่ O(1) ออกมาได้
หัวข้อต่อไป เราจะเริ่มมาเจาะลึกเรื่องของ Code Complexity กันว่า Algorithm ที่ดีและไม่ดีตามนิยามนั้น วัดผลจากอะไร และมีวิธีคิดและไอเดียอย่างไรบ้าง เจอกันในหัวข้อถัดไปครับ