ทำความรู้จักกับ Time Series
รู้จักกับข้อมูล Time Series
ข้อมูล Time Series คือชุดข้อมูลที่ถูกเก็บรวบรวมตามลำดับเวลา โดยแต่ละจุดข้อมูลจะมีการระบุเวลาหรือวันที่ที่ข้อมูลนั้นถูกบันทึกไว้ ข้อมูล Time Series ถูกใช้เพื่อวิเคราะห์แนวโน้มหรือพฤติกรรมของข้อมูลในช่วงเวลาที่แตกต่างกัน เช่น การวิเคราะห์ยอดขายรายเดือน, อุณหภูมิในแต่ละวัน, หรือราคาหุ้นในแต่ละวินาที
ลักษณะของข้อมูล Time Series
- ต่อเนื่องตามเวลา: ข้อมูลแต่ละค่ามีความต่อเนื่องกันและถูกเก็บตามลำดับเวลา เช่น รายวัน, รายเดือน, รายชั่วโมง
- มีลำดับเวลา: ข้อมูลต้องมีลำดับตามเวลาเสมอ ไม่สามารถสับเปลี่ยนลำดับได้
- ถูกใช้เพื่อวิเคราะห์แนวโน้ม: ข้อมูลประเภทนี้มักใช้เพื่อการพยากรณ์หรือคาดการณ์แนวโน้มในอนาคต
ตัวอย่างของข้อมูล Time Series
- ยอดขายรายเดือน: บริษัทบันทึกยอดขายของสินค้าในแต่ละเดือน เพื่อนำไปวิเคราะห์แนวโน้มการขายและวางแผนธุรกิจในอนาคต
- มกราคม: 100,000 บาท
- กุมภาพันธ์: 120,000 บาท
- มีนาคม: 110,000 บาท
- อุณหภูมิรายวัน: ข้อมูลอุณหภูมิที่บันทึกทุกวันในแต่ละเมือง เพื่อนำไปวิเคราะห์แนวโน้มของสภาพอากาศ
- วันที่ 1: 30°C
- วันที่ 2: 32°C
- วันที่ 3: 29°C
- ราคาหุ้นรายวินาที: ข้อมูลราคาหุ้นที่บันทึกทุกวินาทีสำหรับการวิเคราะห์การเปลี่ยนแปลงของตลาดหุ้น
- 09:00:00: 100 บาท
- 09:00:01: 101 บาท
- 09:00:02: 99 บาท
ตัวอย่างข้อมูล Time Series ในรูปแบบ CSV
Date,Sales
2024-01-01,100
2024-01-02,150
2024-01-03,200
2024-01-04,170
2024-01-05,180
ในไฟล์ตัวอย่างนี้ คอลัมน์ Date คือวันที่และคอลัมน์ Sales คือยอดขายของแต่ละวัน ข้อมูลนี้สามารถนำไปใช้ในการสร้างกราฟและวิเคราะห์แนวโน้มได้
การใช้งาน Time Series ใน Pandas
เมื่อเราใช้ Pandas ในการจัดการข้อมูล Time Series เราสามารถใช้ pd.to_datetime() เพื่อแปลงคอลัมน์วันที่เป็นข้อมูลแบบเวลา และใช้ฟังก์ชันต่าง ๆ เพื่อจัดการข้อมูล Time Series ได้ เช่นการคำนวณค่าเฉลี่ยต่อช่วงเวลา หรือการพยากรณ์ข้อมูลในอนาคต
import pandas as pd
import matplotlib.pyplot as plt
# อ่านข้อมูลจาก CSV
df = pd.read_csv('sales_time_series.csv')
# แปลงคอลัมน์ 'Date' ให้เป็น datetime
df['Date'] = pd.to_datetime(df['Date'])
# ตั้งค่า Date เป็น index เพื่อให้ทำงานกับ Time Series ได้ง่ายขึ้น
df.set_index('Date', inplace=True)
# สร้างกราฟแสดงยอดขายรายวัน
df['Sales'].plot()
plt.title('Daily Sales Over Time')
plt.xlabel('Date')
plt.ylabel('Sales')
plt.show()
ผลลัพธ์

ตัวอย่างนี้
- เราอ่านข้อมูลจากไฟล์ CSV และแปลงคอลัมน์วันที่ให้เป็น
datetimeเพื่อให้สามารถใช้ฟังก์ชันของ Time Series ได้อย่างมีประสิทธิภาพ - ใช้
plot()เพื่อแสดงแนวโน้มของยอดขายตามเวลา
Visualizing Time Series
การ Visualize ข้อมูล Time Series ถือเป็นหัวใจสำคัญในการทำ Data Analysis โดยเฉพาะเมื่อเราต้องการตรวจสอบแนวโน้มและการเปลี่ยนแปลงของข้อมูลเมื่อเวลาผ่านไป เราสามารถใช้ Pandas และ Matplotlib ในการสร้างกราฟที่มีความซับซ้อนมากขึ้นเพื่อให้ได้ข้อมูลเชิงลึกออกมา
ข้อมูล Time Series มักมีความถี่ที่แตกต่างกัน เช่น รายวัน, รายเดือน, รายชั่วโมง ในการจัดการความถี่นี้เราสามารถใช้ Pandas เพื่อปรับความถี่ (Resampling) หรือจัดการช่องว่างในข้อมูล (Missing Values)
กราฟยอดฮิตสำหรับ Time Series:
- Line Plot (แผนภูมิเส้น) ใช้แสดงแนวโน้มการเปลี่ยนแปลงของข้อมูลตามช่วงเวลาอย่างต่อเนื่อง
- Scatter Plot (แผนภูมิกระจาย) ใช้ในการแสดงค่าของข้อมูลตามเวลาแต่ละจุด ซึ่งสามารถช่วยตรวจสอบความหนาแน่นหรือความผิดปกติในข้อมูล
- Bar Plot (แผนภูมิแท่ง) ใช้ในการแสดงข้อมูล Time Series ที่มีช่วงเวลาไม่ต่อเนื่อง เช่น ปริมาณการขายรายเดือน
- Heatmap (ฮีทแมป) ใช้ในการแสดงแนวโน้มข้อมูลในรูปแบบของความเข้มสีในช่วงเวลาต่าง ๆ โดยเฉพาะอย่างยิ่งข้อมูลที่มีหลายมิติ
- Autocorrelation Plot ใช้ในการตรวจสอบความสัมพันธ์ของข้อมูล Time Series ในช่วงเวลาต่าง ๆ ของตัวมันเอง
- Seasonal Decomposition Plot ใช้ในการแยกองค์ประกอบแนวโน้มตามฤดูกาล การเปลี่ยนแปลง และความผิดปกติในข้อมูล
เรามาลองดูผ่านตัวอย่างกัน สมมุติว่ามีไฟล์ CSV ชื่อtime_series_data.csv ที่มีโครงสร้างดังนี้
Date,Value
2024-01-01,118
2024-01-02,108
2024-01-03,94
2024-01-04,87
2024-01-05,100
2024-01-06,118
2024-01-07,98
2024-01-08,102
2024-01-09,90
2024-01-10,90
2024-01-11,103
2024-01-12,115
...
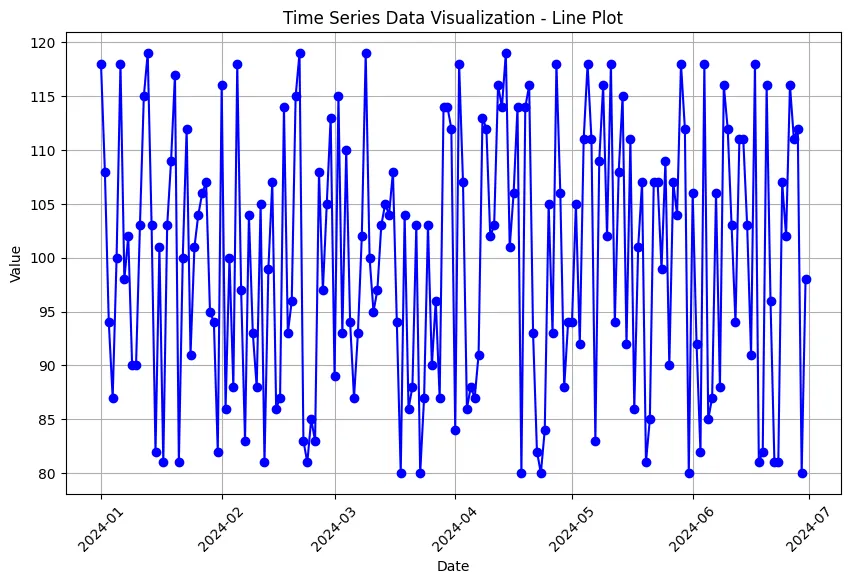
Line Plot
Line Plot และ Time Series เป็นเครื่องมือสำคัญในการวิเคราะห์ข้อมูลที่เปลี่ยนแปลงตามเวลา ซึ่งมักถูกนำมาใช้ในหลากหลายสาขา เช่น การเงิน การตลาด และ data science เพื่อทำความเข้าใจพฤติกรรมและแนวโน้มของข้อมูล ทั้งสองรูปแบบมีประโยชน์ที่หลากหลาย เช่น:
- การแสดงแนวโน้ม (Trend Analysis): ใช้ในการวิเคราะห์แนวโน้มระยะยาว เช่น ยอดขายที่เพิ่มขึ้นหรือลดลง หรือการเปลี่ยนแปลงของอุณหภูมิในช่วงเวลาหนึ่ง
- การตรวจสอบความผิดปกติ (Anomaly Detection): ช่วยระบุความผิดปกติในข้อมูล เช่น การลดลงอย่างรวดเร็วของผู้ใช้งาน หรือการเพิ่มขึ้นผิดปกติในค่าใช้จ่าย
- การพยากรณ์ (Forecasting): เป็น�พื้นฐานสำหรับการคาดการณ์อนาคต เช่น การพยากรณ์ยอดขายหรือความต้องการสินค้า
- การเปรียบเทียบข้อมูล (Comparison): สามารถเปรียบเทียบข้อมูลหลายชุดที่เกิดขึ้นในช่วงเวลาเดียวกันเพื่อดูความสัมพันธ์
ด้วยคุณสมบัติเหล่านี้ Line Plot และ Time Series จึงเป็นเครื่องมือที่ขาดไม่ได้สำหรับการตัดสินใจที่มีข้อมูลรองรับและการวางแผนเชิงกลยุทธ์ได้ (เราจะมีมาเจาะลึกกันเพิ่มเติมอีกทีในหัวข้อ machine learning กัน)
นี่คือตัวอย่าง python code ที่ใช้กับ Time Series
import pandas as pd
import matplotlib.pyplot as plt
# อ่านข้อมูลจากไฟล์ CSV
data = pd.read_csv('time_series_data.csv')
# แปลงคอลัมน์ 'Date' ให้เป็นรูปแบบ datetime
data['Date'] = pd.to_datetime(data['Date'])
# สร้าง Line Plot
plt.figure(figsize=(10, 6))
plt.plot(data['Date'], data['Value'], marker='o', linestyle='-', color='b')
plt.title('Time Series Data Visualization - Line Plot')
plt.xlabel('Date')
plt.ylabel('Value')
plt.grid(True)
plt.xticks(rotation=45)
plt.show()
ผลลัพธ์
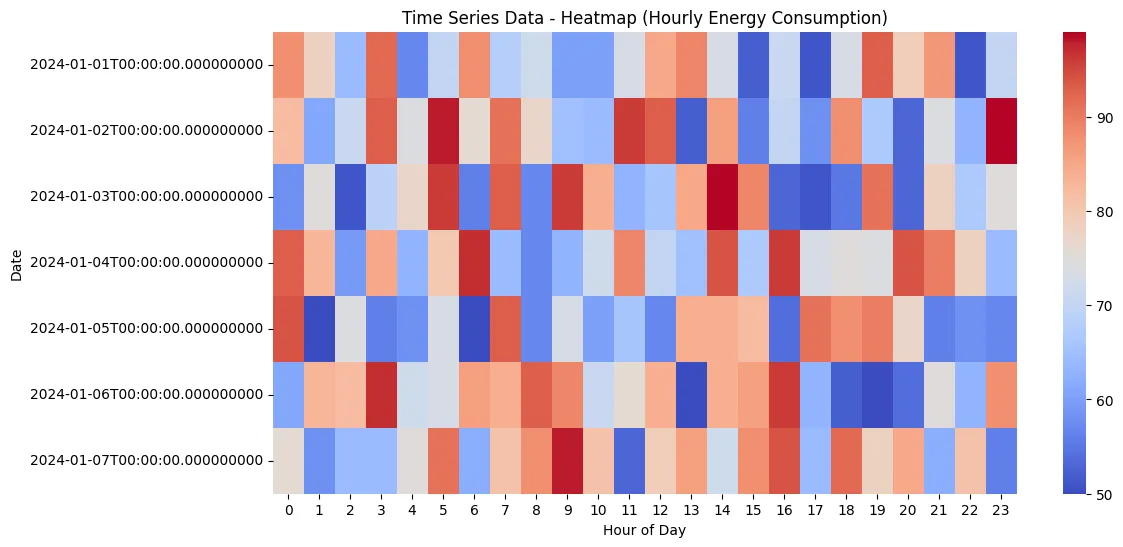
Heatmap
Heatmap และ Time Series เป็นเครื่องมือที่ทรงพลังในการวิเคราะห์ข้อมูลโดยเฉพาะข้อมูลที่เกี่ยวข้องกับเวลา Heatmap ช่วยเน้นความเข้มของข้อมูลในรูปแบบภาพที่เข้าใจง่าย ในขณะที่ Time Series มุ่งเน้นการแสดงความเปลี่ยนแปลงเมื่อเวลาผ่านไป การใช้ร่วมกันหรือแยกกันมีประโยชน์ดังนี้
- การแสดงรูปแบบที่ชัดเจน (Pattern Recognition):
- Heatmap ช่วยแสดงรูปแบบความเข้มของข้อมูล เช่น ช่วงเวลาที่มีการใช้งานสูงสุดในระบบ หรือช่วงที่เกิด��กิจกรรมสำคัญ
- Time Series ช่วยแสดงความต่อเนื่องและลำดับเวลาของเหตุการณ์ ทำให้เห็นพฤติกรรมในระยะยาว
- การวิเคราะห์ฤดูกาล (Seasonality Analysis):
- Heatmap สามารถเน้นความแปรผันที่เกิดในแต่ละช่วงเวลา เช่น การขายสินค้าที่เพิ่มขึ้นในช่วงเทศกาล
- Time Series ช่วยระบุความถี่ของการเปลี่ยนแปลง เช่น รูปแบบรายวัน รายเดือน หรือรายปี
- การตรวจจับความผิดปกติ (Anomaly Detection):
- Heatmap ช่วยเน้นจุดที่ข้อมูลมีค่าผิดปกติ เช่น จุดที่มีการใช้งานสูงเกินปกติในเครือข่าย
- Time Series ช่วยตรวจจับความผิดปกติในความต่อเนื่องของข้อมูล เช่น การลดลงของยอดขายในช่วงที่ไม่ควรเกิด
- การเปรียบเทียบหลายมิติ (Multidimensional Comparison):
- Heatmap แสดงข้อมูลหลายมิติในมุมมองเดียว เช่น การเปรียบเทียบระดับการใช้พลังงานของแต่ละอาคารในช่วงเวลาเดียวกัน
- Time Series ช่วยแยกการเปรียบเ��ทียบตามลำดับเวลา เช่น การเปรียบเทียบยอดขายในแต่ละเดือนของร้านค้า
- การวางแผนและพยากรณ์ (Planning and Forecasting):
- Heatmap ช่วยให้มองเห็นภาพรวมของการเปลี่ยนแปลงในอดีต ซึ่งเป็นพื้นฐานสำหรับการวางแผน
- Time Series ช่วยสร้างโมเดลพยากรณ์ที่มีประสิทธิภาพในการคาดการณ์ข้อมูลในอนาคต
ตัวอย่าง python code กับ Heatmap
import seaborn as sns
import numpy as np
# สร้างข้อมูล Time Series สำหรับ Heatmap
# สมมุติข้อมูลสำหรับการใช้พลังงานในแต่ละชั่วโมงเป็นเวลา 7 วัน
dates = pd.date_range(start='2024-01-01', periods=7)
hours = np.arange(0, 24)
np.random.seed(42)
data_heatmap = np.random.randint(50, 100, size=(7, 24))
# สร้าง DataFrame สำหรับ Heatmap
df_heatmap = pd.DataFrame(data_heatmap, index=dates, columns=hours)
# สร้าง Heatmap
plt.figure(figsize=(12, 6))
sns.heatmap(df_heatmap, cmap='coolwarm', annot=False)
plt.title('Time Series Data - Heatmap (Hourly Energy Consumption)')
plt.xlabel('Hour of Day')
plt.ylabel('Date')
plt.show()
ผลลัพธ์
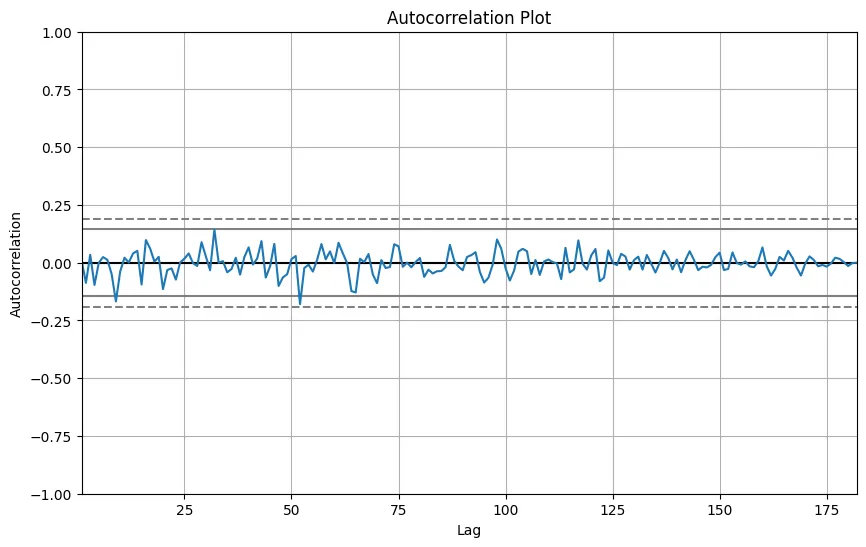
Autocorrelation Plot
Autocorrelation Plot คือกราฟที่ใช้ในการวิเคราะห์ความสัมพันธ์ของค่าข้อมูลในช่วงเวลาต่าง ๆ กับค่าของตัวเองในอดีตหรืออนาคต การวิเคราะห์นี้มีประโยชน์ในการตรวจสอบว่าข้อมูลที่เรามีมีรูปแบบหรือแนวโน้มที่ซ้ำ ๆ กันตามช่วงเวลา หรือมีความสัมพันธ์ในลักษณะที่เรียกว่า autocorrelation (การสัมพันธ์ตัวเอง) หรือไม่
การตีความผลจาก Autocorrelation Plot:
- ค่าสูง (positive autocorrelation) แสดงว่าข้อมูลมีแนวโน้มไปในทิศทางเดียวกัน เช่น ถ้าค่าในอดีตสูง ค่าปัจจุบันก็มักจะสูงตาม และในทางกลับกัน
- ค่าต่ำ (negative autocorrelation) แสดงว่าข้อมูลมีแนวโน้มไปในทิศทางตรงกันข้าม เช่น ถ้าค่าในอดีตสูง ค่าปัจจุบันจะต่ำลง
- ค่าใกล้ศูนย์ แสดงว่าข้อมูลไม่ค่อยมีความสัมพันธ์กันตาม lag นั้น ๆ
ตัวอย่างการสร้าง Autocorrelation Plot ด้วย Python:
from pandas.plotting import autocorrelation_plot
# สร้าง Autocorrelation Plot สำหรับข้อมูล
plt.figure(figsize=(10, 6))
autocorrelation_plot(data['Value'])
plt.title('Autocorrelation Plot')
plt.show()
ผลลัพธ์
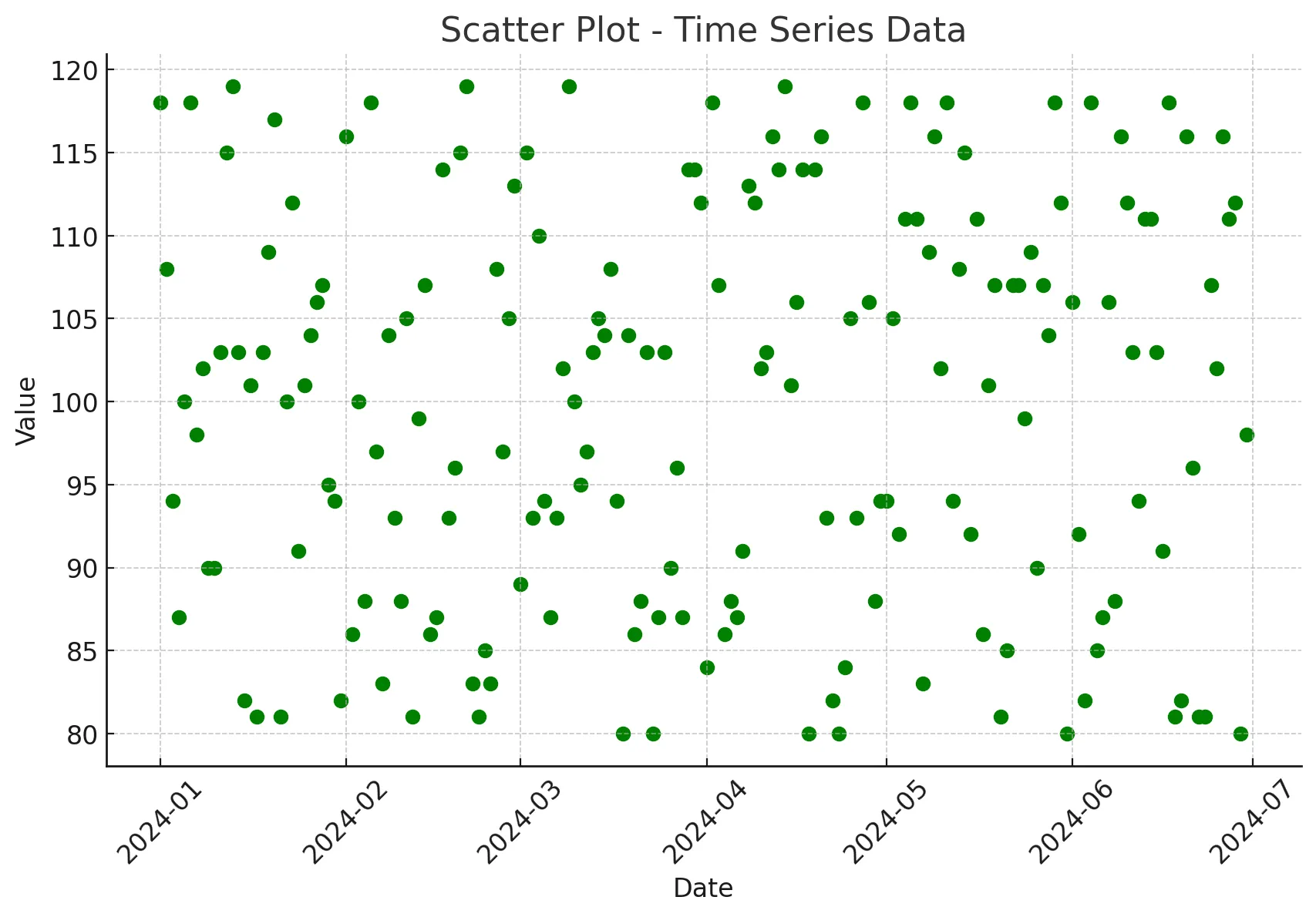
Scatter Plot
Scatter Plot และ Time Series เป็นเครื่องมือสำคัญในการวิเคราะห์ข้อมูลที่มีมิติของเวลา และช่วยในการระบุรูปแบบหรือความสัมพันธ์ที่ซับซ้อนในข้อมูล ทั้งสองมีบทบาทที่แตกต่างกันและสามารถใช้งานร่วมกันได้อย่างมีประสิทธิภาพ
- การค้นหารูปแบบความสัมพันธ์ (Correlation Analysis):
- Scatter Plot: ช่วยแสดงความสัมพันธ์ระหว่างตัวแปร เช่น ความสัมพันธ์ระหว่างยอดขายกับจำนวนลูกค้าในช่วงเวลาต่าง ๆ
- Time Series: ช่วยระบุว่าความสัมพันธ์นั้นเปลี่ยนแปลงไปอย่างไรเมื่อเวลาผ่านไป
- การวิเคราะห์ความผิดปกติ (Anomaly Detection):
- Scatter Plot: ใช้ระบุจุดที่ไม่สอดคล้องกับแนวโน้ม เช่น จุดที่ยอดขายพุ่งสูงหรือลดลงอย่างผิดปกติ
- Time Series: ช่วยดูความต่อเนื่องและเปรียบเทียบว่าความผิดปกติเหล่านั้นเป็นเหตุการณ์เฉพาะหรือเกิดขึ้นซ้ำ ๆ
- การแสดงความแปรผัน (Variability Analysis):
- Scatter Plot: แสดงการกระจายตัวของข้อมูลเพื่อดูความแปรผันในช่วงเวลาหนึ่ง
- Time Series: แสดงแนวโน้มของความแปรผันในระยะยาว
- การทดสอบสมมติฐาน (Hypothesis Testing):
- Scatter Plot: ใช้ทดสอบสมมติฐานเกี่ยวกับความสัมพันธ์ของตัวแปร เช่น การใช้จ่ายโฆษณากับยอดขาย
- Time Series: ใช้ตรวจสอบว่าสมมติฐานนั้นยังคงเป็นจริงในระยะยาวหรือไม่
- การวางแผนและพยากรณ์ (Planning and Forecasting):
- Scatter Plot: ช่วยวิเคราะห์ข้อมูลในมิติหนึ่งเพื่อสร้างตัวแปรพยากรณ์ที่เหมาะสม
- Time Series: นำข้อมูลที่ได้ไปใช้สร้างแบบจำลองเพื่อพยากรณ์ข้อมูลในอนาคต
และนี่คือตัวอย่าง python code กับ Scatter Plot
import pandas as pd
import matplotlib.pyplot as plt
# อ่านข้อมูลจากไฟล์ CSV
data = pd.read_csv('time_series_data.csv')
# แปลงคอลัมน์ 'Date' ให้เป็นรูปแบบ datetime
data['Date'] = pd.to_datetime(data['Date'])
# สร้าง Scatter Plot
plt.figure(figsize=(10, 6))
plt.scatter(data['Date'], data['Value'], color='g', marker='o')
plt.title('Scatter Plot - Time Series Data')
plt.xlabel('Date')
plt.ylabel('Value')
plt.grid(True)
plt.xticks(rotation=45)
plt.show()
ผลลัพธ์
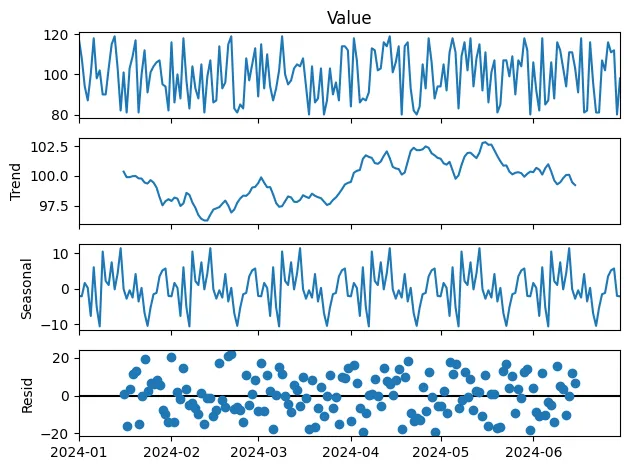
Seasonal Decomposition Plot
Seasonal Decomposition Plot เป็นเครื่องมือที่ใช้แยกองค์ประกอบของข้อมูล Time Series ออกเป็นส่วน ๆ ได้แก่ แนวโน้ม (Trend), ฤดูกาล (Seasonality), และส่วนที่เหลือหรือความผิดปกติ (Residual) เพื่อทำความเข้าใจพฤติกรรมของข้อมูลในแต่ละมิติ การใช้ Seasonal Decomposition Plot ช่วยให้การวิเคราะห์ Time Series มีความลึกซึ้งมากขึ้น โดยประโยชน์ที่สำคัญมีดังนี้:
- การแยกองค์ประกอบเพื่อการวิเคราะห์เชิงลึก (Component Analysis):
- แยกแนวโน้มระยะยาว (Trend) เพื่อดูการเปลี่ยนแปลงอย่างต่อเนื่องในข้อมูล
- วิเคราะห์ฤดูกาล (Seasonality) เพื่อทำความเข้าใจรูปแบบที่เกิดซ้ำในช่วงเวลาหนึ่ง เช่น รายเดือนหรือรายปี
- ระบุความผิดปกติ (Residual) เพื่อตรวจจับเหตุการณ์ที่ไม่สามารถอธิบายได้ด้วยแนวโน้มหรือฤดูกาล
- การวิเคราะห์แนวโน้มระยะยาว (Long-term Trend Analysis):
- ช่วยให้เห็นทิศทางของข้อมูล เช่น ยอดขายที่เติบโตขึ้นอย่างต่อเนื่องหรือการลดลงในระยะยาว
- การระบุรูปแบบตามฤดูกาล (Seasonality Identification):
- ช่วยระบุช่วงเวลาที่มีผลกระทบสูง เช่น ยอดขายที่เพิ่มขึ้นในช่วงเทศกาล
- การตรวจสอบความผิดปกติ (Anomaly Detection):
- ช่วยให้มองเห็นจุดที่ข้อมูลไม่สอดคล้องกับแนวโน้มหรือฤดูกาล เช่น การลดลงของยอดขายที่ไม่ได้คาดการณ์ไ�ว้
- การสร้างแบบจำลองพยากรณ์ (Forecasting Model Development):
- ช่วยแยกส่วนที่มีความสำคัญเพื่อนำไปพัฒนาแบบจำลองการพยากรณ์ที่แม่นยำ เช่น ใช้เฉพาะแนวโน้มหรือฤดูกาลในการสร้างแบบจำลอง
โดยการ Plot Seasonal Decomposition Plot จะต้องลง library statsmodels เพิ่ม
pip install statsmodels
และใช้ python code ประมาณนี้
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
# อ่านข้อมูลจากไฟล์ CSV
data = pd.read_csv('time_series_data.csv')
# แปลงคอลัมน์ 'Date' ให้เป็นรูปแบบ datetime
data['Date'] = pd.to_datetime(data['Date'])
# ตั้งค่า index ให้กับคอลัมน์ 'Date'
data.set_index('Date', inplace=True)
# Seasonal Decomposition
# เนื่องจากข้อมูลเป็นรายวัน กำหนดช่วงเวลา (period) เป็น 30 (สมมุติเป็นรอบเดือน)
result = seasonal_decompose(data['Value'], model='additive', period=30)
# Plotting Seasonal Decomposition (Trend, Seasonal, Residual)
result.plot()
plt.show()
ผลลัพธ์