การอ่านไฟล์
การดึงข้อมูล
ตอนนี้เรารู้จัก Numpy library ที่ใช้สำหรับการคำนวน และ Pandas library ที่ใช้สำหรับจัดการ Data แล้ว ตอนนี้เดี๋ยวเราจะมาลองกับไฟล์จริงๆ กันดูบ้าง ตัวอย่างที่เราหยิบมาจะมีทั้งหมด 3 อย่างด้วยกันนันคือ
- อ่าน CSV
- อ่าน Excel
- อ่าน JSON
- อ่านผ่าน SQL
อ่าน CSV
เราสามารถใช้ Pandas ในการอ่านไฟล์ CSV ได้อย่างง่ายดาย โดยใช้ฟังก์ชัน read_csv() ที่ Pandas มีให้ ซึ่งรองรับการอ่านไฟล์ CSV จากที่เก็บไฟล์ในเครื่องหรือจาก URL ได้
ตัวอย่างการใช้งาน
import pandas as pd
# อ่านไฟล์ CSV
df = pd.read_csv('file.csv')
# แสดงข้อมูล 5 แถวแรก
print(df.head())
จบครับ สั้นๆง่ายๆแค่นี้เลย 555 เราจะขอยกตัวอย่างกับไฟล์ CSV นี้นะครับ สมมุติว่าเรามีไฟล์ CSV ที่มีข้อมูลแบบนี้
Name,Age,Department,Salary
John Doe,28,Engineering,50000
Jane Smith,35,Marketing,60000
Emily Davis,22,Sales,45000
Michael Brown,40,HR,65000
Laura Wilson,30,Engineering,55000
ไฟล์ CSV นี้ประกอบด้วยข้อมูลพนักงาน 5 คน โดยมี 4 คอลัมน์ ได้แก่:
- Name: ชื่อของพนักงาน
- Age: อายุ
- Department: แผนกที่ทำงาน
- Salary: เงินเดือน
CSV (Comma-Separated Values) คือรูปแบบไฟล์ชนิดหนึ่งที่ใช้สำหรับการเก็บข้อมูลในรูปแบบตาราง โดยแต่ละแถว (row) ในไฟล์ CSV จะเก็บข้อมูลของแต่ละบรรทัดในตาราง ส่วนข้อมูลในแต่ละคอลัมน์ (column) จะถูกคั่นด้วยเครื่องหมายจุลภาค (,)
เนื่องจากไฟล์ CSV เป็นเพียงไฟล์ข้อความธรรมดา (plain text file) ข้อมูลจึงถูกบันทึกเป็นข้อความที่สามารถอ่านได้ด้วยมนุษย์และไม่ต้องการการเข้ารหัสซับซ้อน ทำให้สามารถเปิดดูได้ใน text editor ทั่วไป เช่น Notepad, Sublime Text, หรือ VS Code นอกจากนี้ยังสามารถเปิดด้วยโปรแกรมสเปรดชีต เช่น Excel หรือ Google Sheets ได้อย่างง่ายดาย
นี่เลยเป็นข้อดีของ CSV file ที่ developer มักเลือกใช้กันแทน Excel file เพราะสามารถตรวจสอบข้อมูลได้ง่าย + ไม่ต้องกังวลเรื่องของ software ที่ใช้เปิดด้วย (เป็นข้อดีทั้ง developer และทั้งกับตัวของ software เอง)
เราจะลอง save file csv นี้ไว้ที่ employees.csv
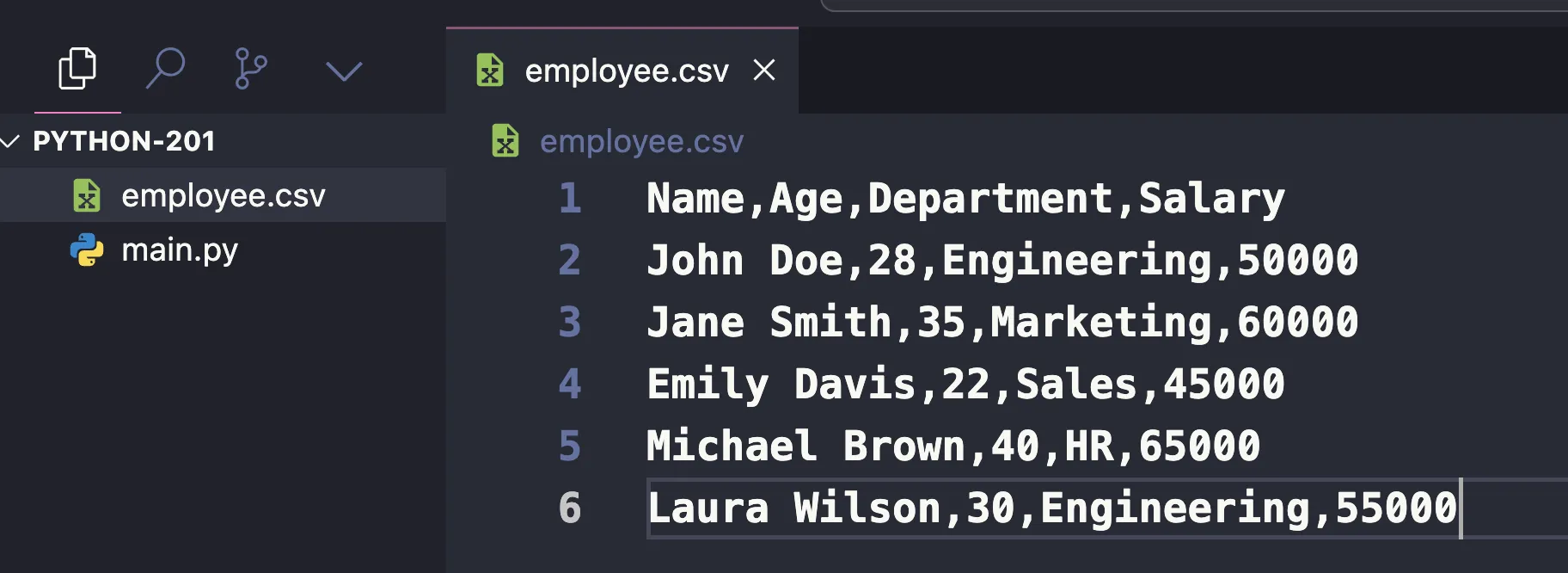
จากนั้นลองอ่านไฟล์ด้วย Pandas
import pandas as pd
# อ่านไฟล์ employees.csv
df = pd.read_csv('employees.csv')
# แสดงข้อมูล
print(df)
ผลลัพธ์ก็จะได้ออกมาตามนี้
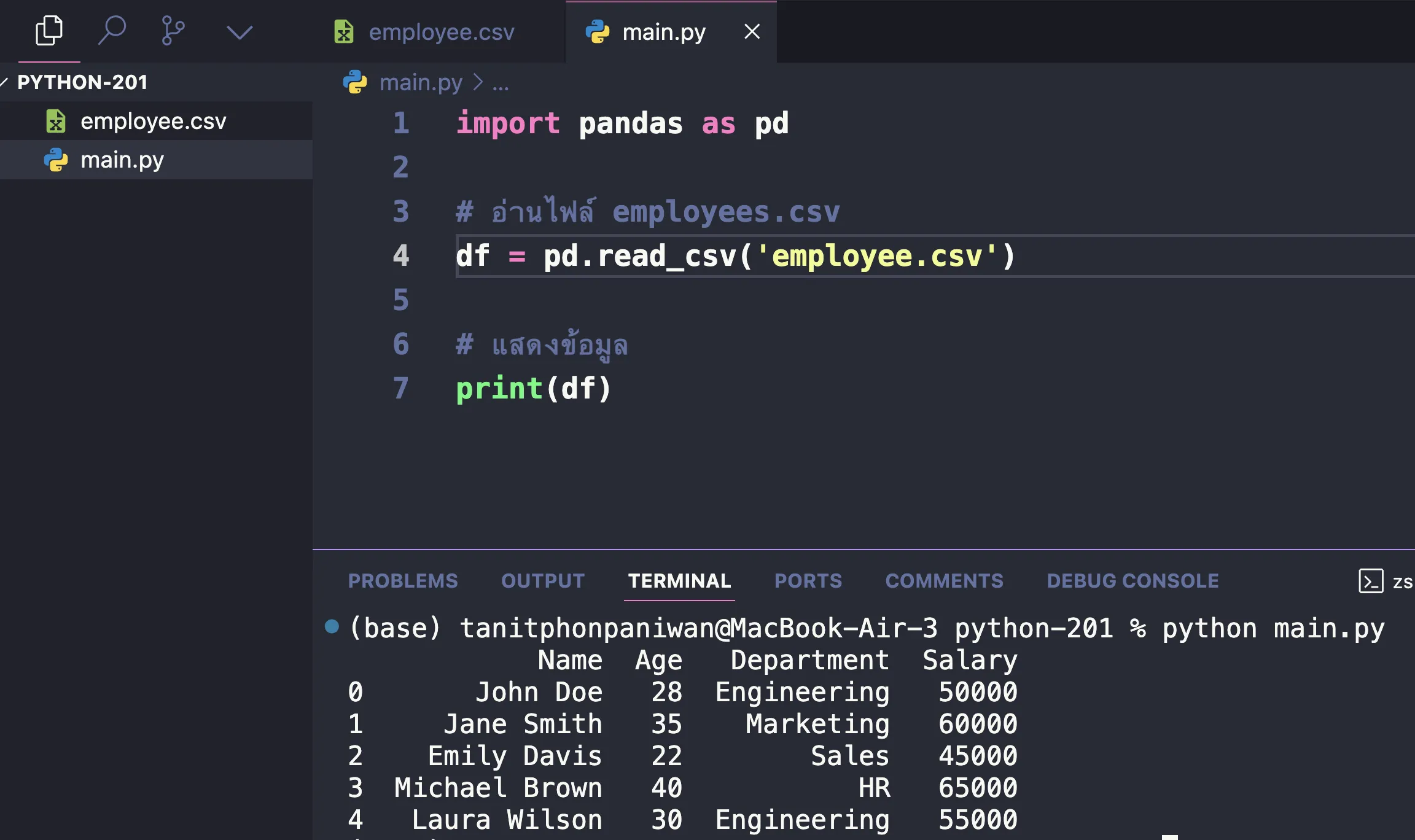
สังเกตนะครับว่า ในตัวอย่างนี้:
- เราใช้
read_csv()เพื่อโหลดข้อมูลจากไฟล์ CSV ที่มีชื่อว่า employee.csv - จากนั้นใช้
print(df)เพื่อแสดงข้อมูลทั้งหมดที่อยู่ใน DataFrame
ที่เหลือ เราก็จะสามารถจัดการข้อมูลด้วยคำสั่ง DataFrame ตามที่เราเรียนรู้ไปก่อนหน้านี้ได้เลย
คุณสมบัติอื่นๆของ read_csv()
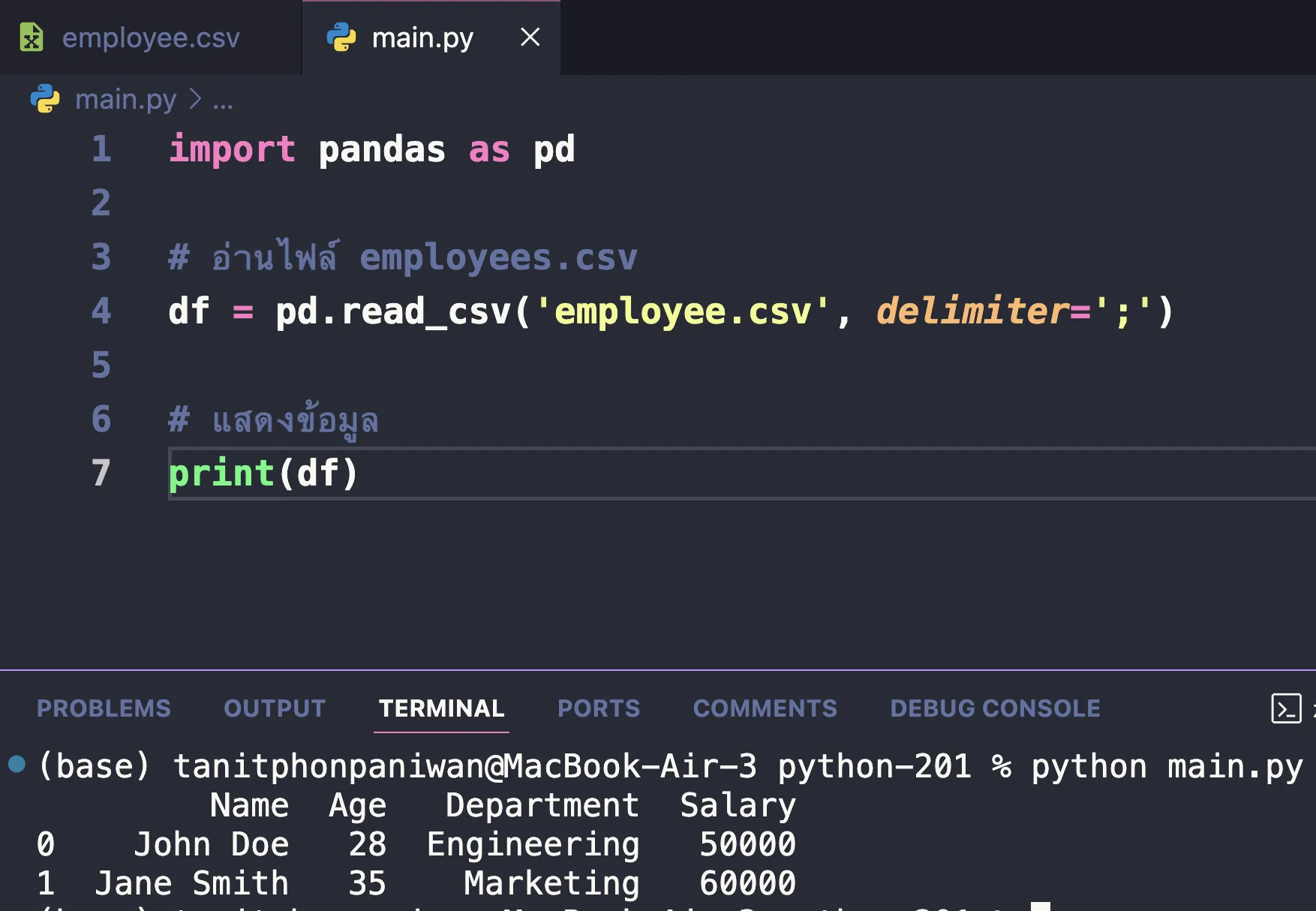
- กำหนดต�ัวคั่น (Delimiter): หากไฟล์ CSV ใช้ตัวคั่นที่ไม่ใช่เครื่องหมายจุลภาค (
,เช่น;หรือ|) เราสามารถกำหนดได้โดยใช้พารามิเตอร์delimiter
df = pd.read_csv('employees.csv', delimiter=';')
ตัวอย่าง csv ที่ใช้ท่านี้ได้
Name;Age;Department;Salary
John Doe;28;Engineering;50000
Jane Smith;35;Marketing;60000
ผลลัพธ์
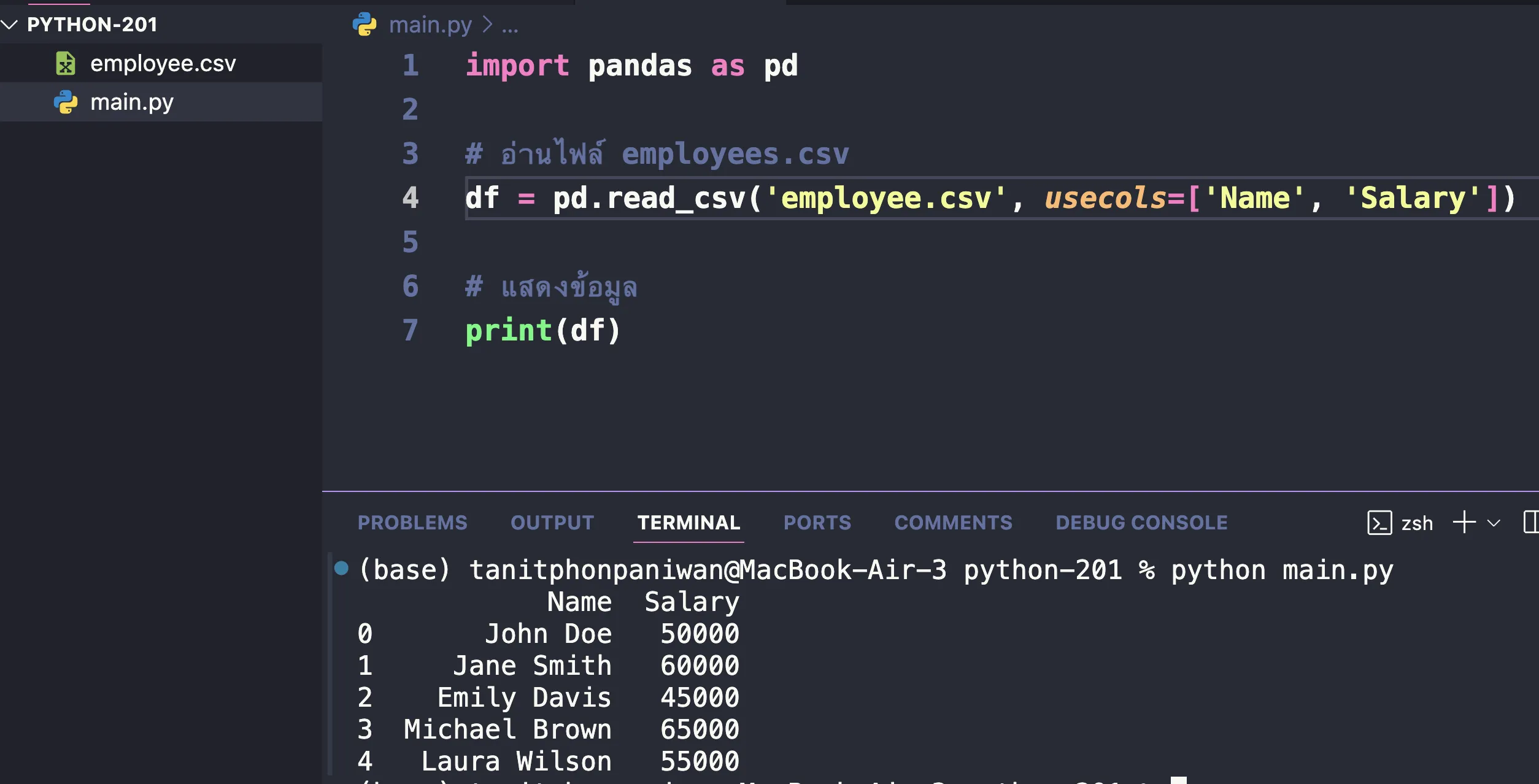
- เลือกเฉพาะบางคอลัมน์: หากต้องการโหลดเฉพาะบางคอลัมน์ สามารถระบุชื่อคอลัมน์ที่ต้องการได้
import pandas as pd
# อ่านไฟล์ employees.csv
df = pd.read_csv('employee.csv', usecols=['Name', 'Salary'])
# แสดงข้อมูล
print(df)
ผลลัพธ์
อ่าน Excel
เราสามารถใช้ Pandas ใน Python เพื่ออ่านไฟล์ Excel ได้อย่างง่ายดายโดยใช้ฟังก์ชัน read_excel ของ Pandas ด้านล่างนี้คือตัวอย่างโค้ดสำหรับการอ่านไฟล์ Excel
import pandas as pd
# อ่านไฟล์ Excel
file_path = 'employees_data.xlsx' # เปลี่ยนเป็น path ที่เก็บไฟล์
df = pd.read_excel(file_path)
# แสดงข้อมูลที่อ่านมา
print(df)
สมมุติไฟล์ employees_data.xlsx มีหน้าตาแบบนี้
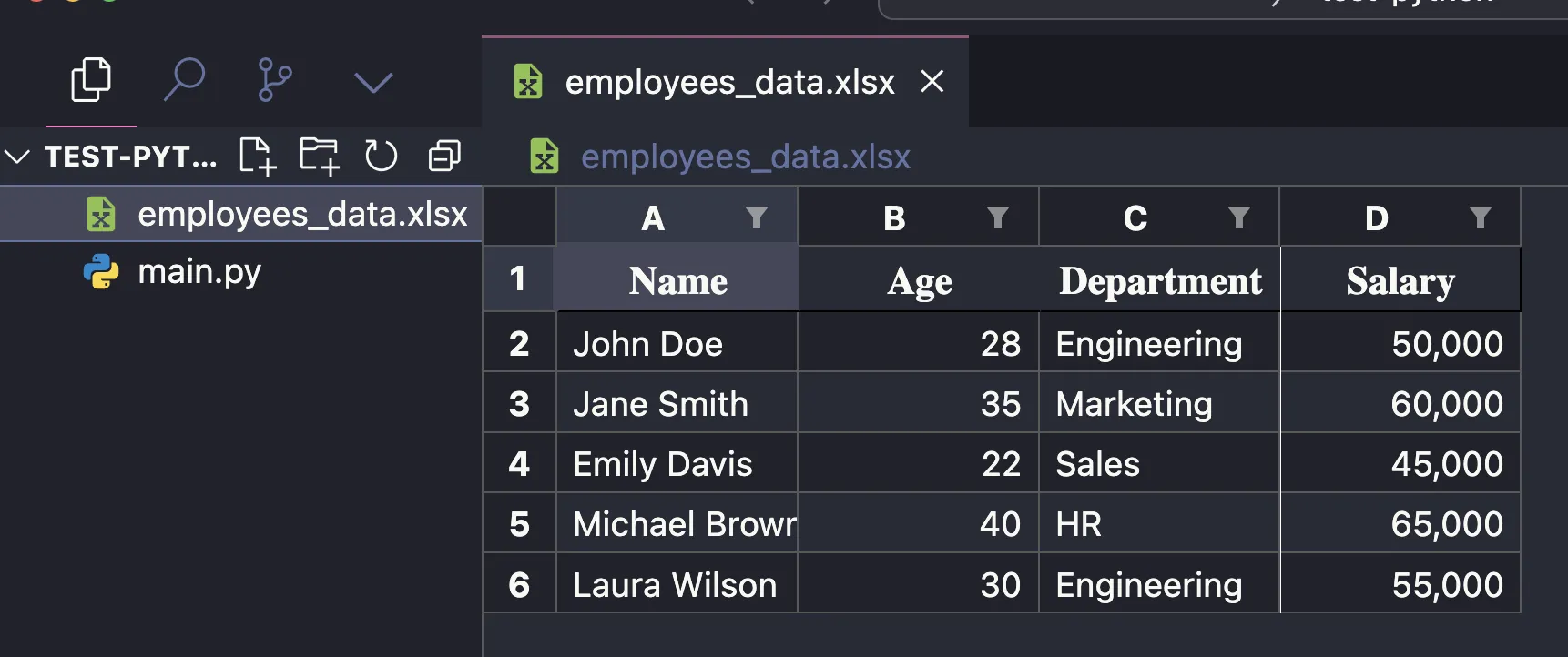
โดย step แรกจะต้องลง library ที่ทำให้ pandas support การอ่าน excel นั่นก็คือ library openpyxl (https://openpyxl.readthedocs.io/en/stable/)
openpyxlคือไลบรารีใน Python ที่ใช้สำหรับการอ่านและเขียนไฟล์ Excel ในฟอร์แมต.xlsx(Excel Open XML Spreadsheet) โดยไม่ต้องใช้ Microsoft Excel เอง ไลบรารีนี้สามารถทำงานกับไฟล์ Excel ที่มีข้อมูล, สูตรคำนวณ, รูปแบบการจัดการเซลล์, และการจัดการกราฟิกต่าง ๆ ได้
คำสั่งสำหรับลง library openpyxl
pip install openpyxl
เมื่อลงเรียบร้อย ให้ลองทำการ run code ดู ก็จะได้ผลลัพธ์การ run เป็นแบบเดียวกับ Dataframe ของ Pandas ในข้อมูลประเภทอื่นๆออกมาได้
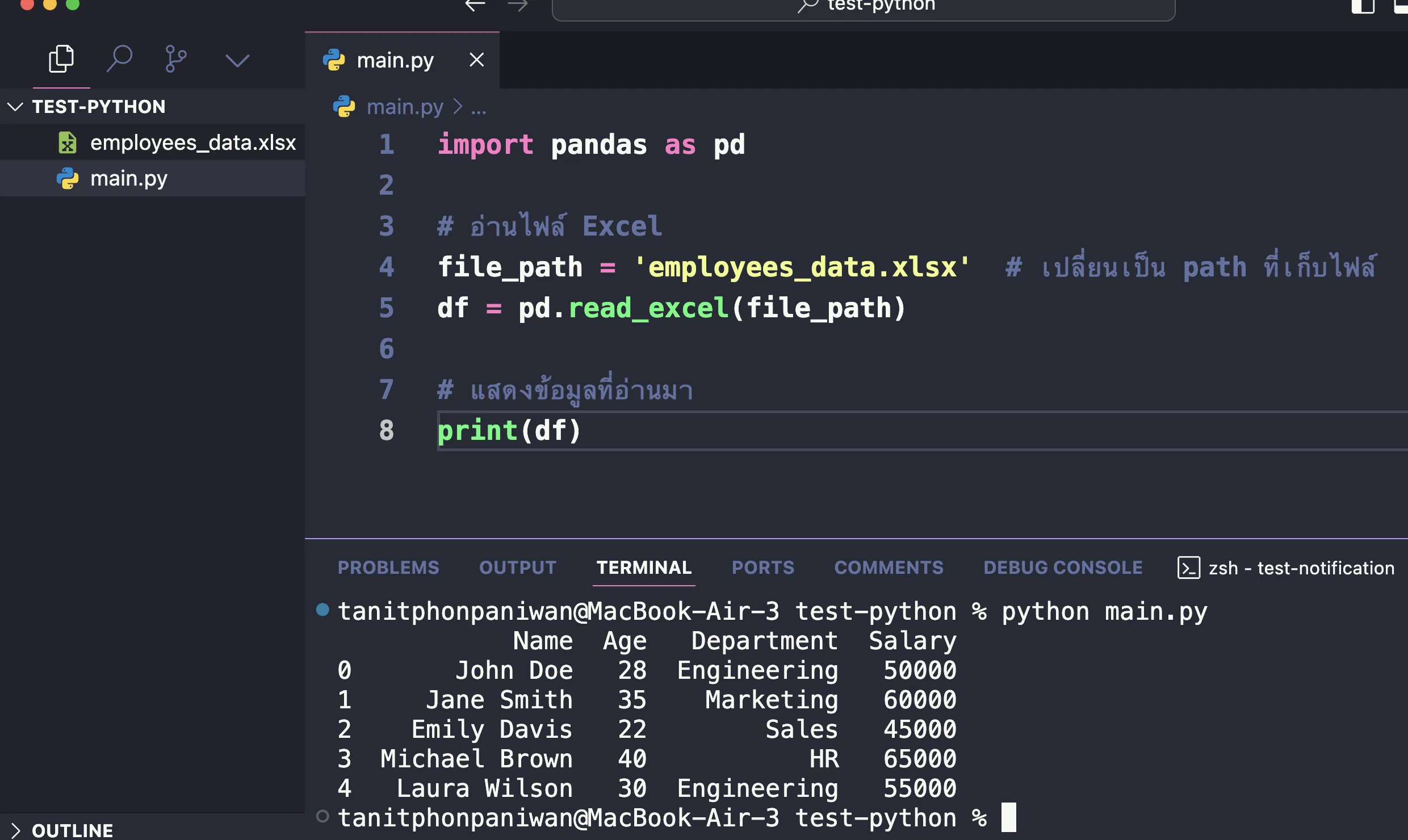
สังเกตนะครับว่า ในตัวอย่างนี้:
- เราใช้
read_excel()เพื่อโหลดข้อมูลจากไฟล์ CSV ที่มีชื่อว่าemployees_data.xlsxเข้ามา - จากนั้นใช้
print(df)เพื่อแสดงข้อมูลทั้งหมดที่อยู่ใน DataFrame (ที่เป็นวิธีเดียวกันกับ csv)
อ่าน JSON
เราสามารถใช้ Pandas และโมดูล requests ใน Python เพื่อดึงข้อมูลจาก API และนำข้อมูลที่ได้มาเข้าใน DataFrame ได้เช่นกัน
โดยในตัวอย่างนี้ เราจะลองจาก public API อย่าง https://jsonplaceholder.typicode.com/users ที่เป็นการดึงข้อมูล mock ของ user และได้ผลลัพธ์เป็น JSON ออกมา
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "[email protected]",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
},
{ /* ... */ }
]
และนี่คือตัวอย่าง code python ที่เป็นการใช้งานผสมระหว่าง request และ pandas
import pandas as pd
import requests
# ดึงข้อมูลจาก API
url = 'https://jsonplaceholder.typicode.com/users'
response = requests.get(url)
# ตรวจสอบว่าการดึงข้อมูลสำเร็จหรือไม่
if response.status_code == 200:
data = response.json() # แปลงข้อมูลจาก JSON เป็น Python object (list of dicts)
# สร้าง DataFrame จากข้อมูลที่ได้
df = pd.DataFrame(data)
# แสดงข้อมูล
print(df)
print(df.columns)
else:
print(f'Error: {response.status_code}')
Idea หลักๆของ code นี้คือ
pandasนั้นสามารถอ่านข้อมูลเป็น JSON ได้อยู่แล้ว (ดั่งที่เราได้ลองใน pandas ใน section ก่อนหน้า)- ดังนั้น หากเราสามารถดึง API มาในรูปแบบ JSON ได้ = เราสามารถทำให้ข้อมูลมาอยู่ในรูปแบบของ dataframe ได้
- คำสั่งการยิง API เพื่อดึงข้อมูลของ python คือ library
request - ใช้คำสั่ง
requests.get(url)สำหรับดึงข้อมูลมาและท้ายที่สุดก็นำผลลัพธ์ JSON นั้น load เข้า dataframe ด้วยคำสั่งpd.DataFrame(data)ได้เช่นเดิม
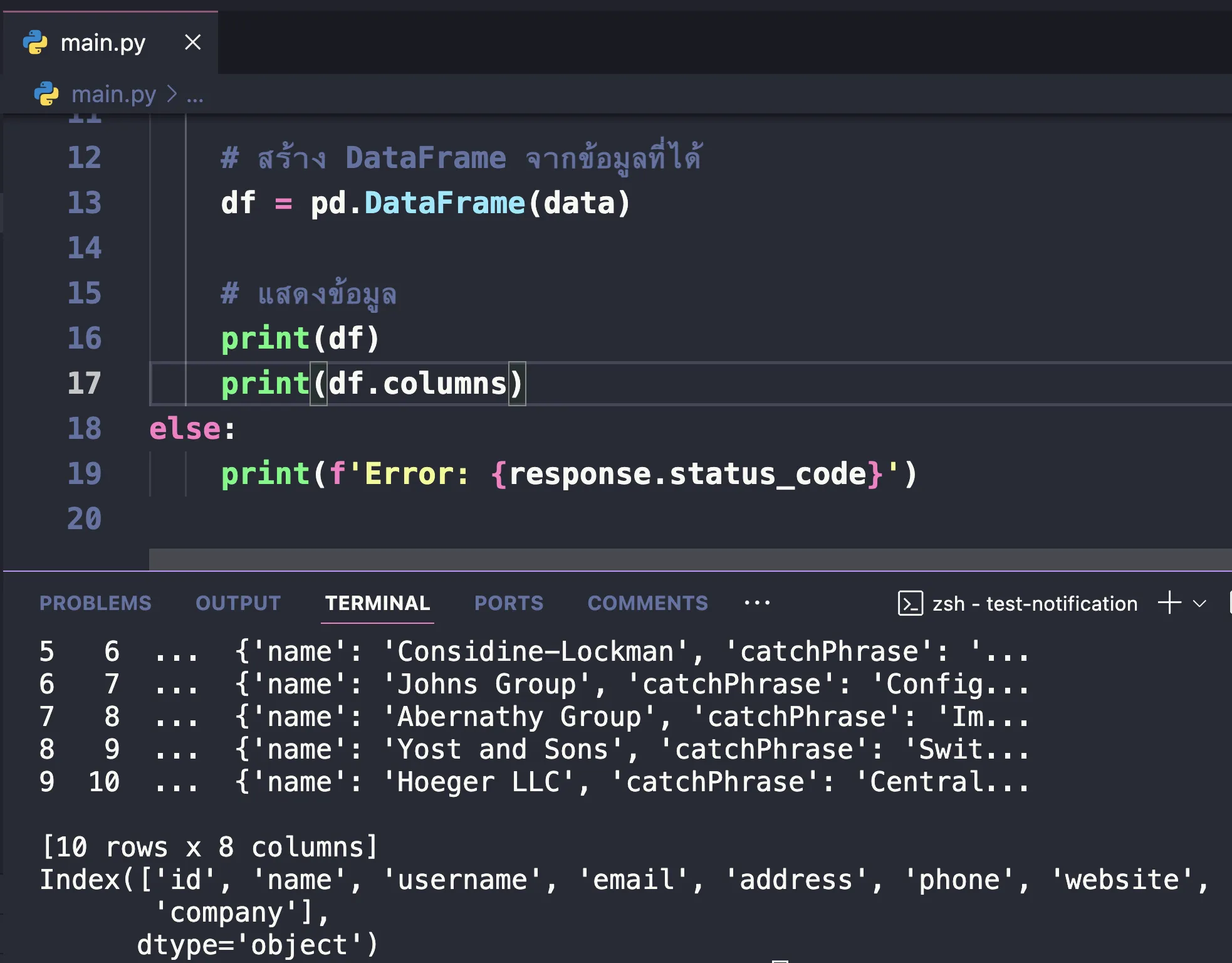
ผลลัพธ์ที่ได้ ก็จะได้เป็นลักษณะแบบนี้ออกมา
อ่าน SQL
แน่นอน รวมถึงข้อมูลประเภท SQL ด้วยเช่นกัน pandas สามารถอ่านข้อมูลประเภท SQL เข้า dataframe ได้
โดยการใช้ Pandas อ่านข้อมูลจาก SQL ซึ่งในทีนี้ เราจะขอใช้ SQLite database (เนื่องจากเป็น database ประเภท file ที่สามารถใช้งานได้โดยไม่จำเป็นต้องลง program อื่นๆเพิ่ม) โดย สามารถทำได้โดยใช้ library อย่าง sqlite3 หรือ sqlalchemy เพื่อเชื่อมต่อกับฐานข้อมูล จากนั้นใช้ฟังก์ชัน read_sql_query ของ Pandas เพื่อนำข้อมูลมาเก็บไว้ใน DataFrame ตัวอย่างนี้จะใช้ sqlite3 ในการเชื่อมต่อกับ SQLite database
** หัวข้อนี้เราจะแนะนำ Database ให้เห็นเป็น way ของการใช้งานก่อน สำหรับ database ฉบับเต็มเราจะมี section แยกแนะนำกันอีกที
เริ่มต้นให้เราลองสร้างไฟล์ของ SQLite ขึ้นมาก่อน โดย file สำหรับ database sqlite นั้นจะเป็นสกุล .db เช่น example.db
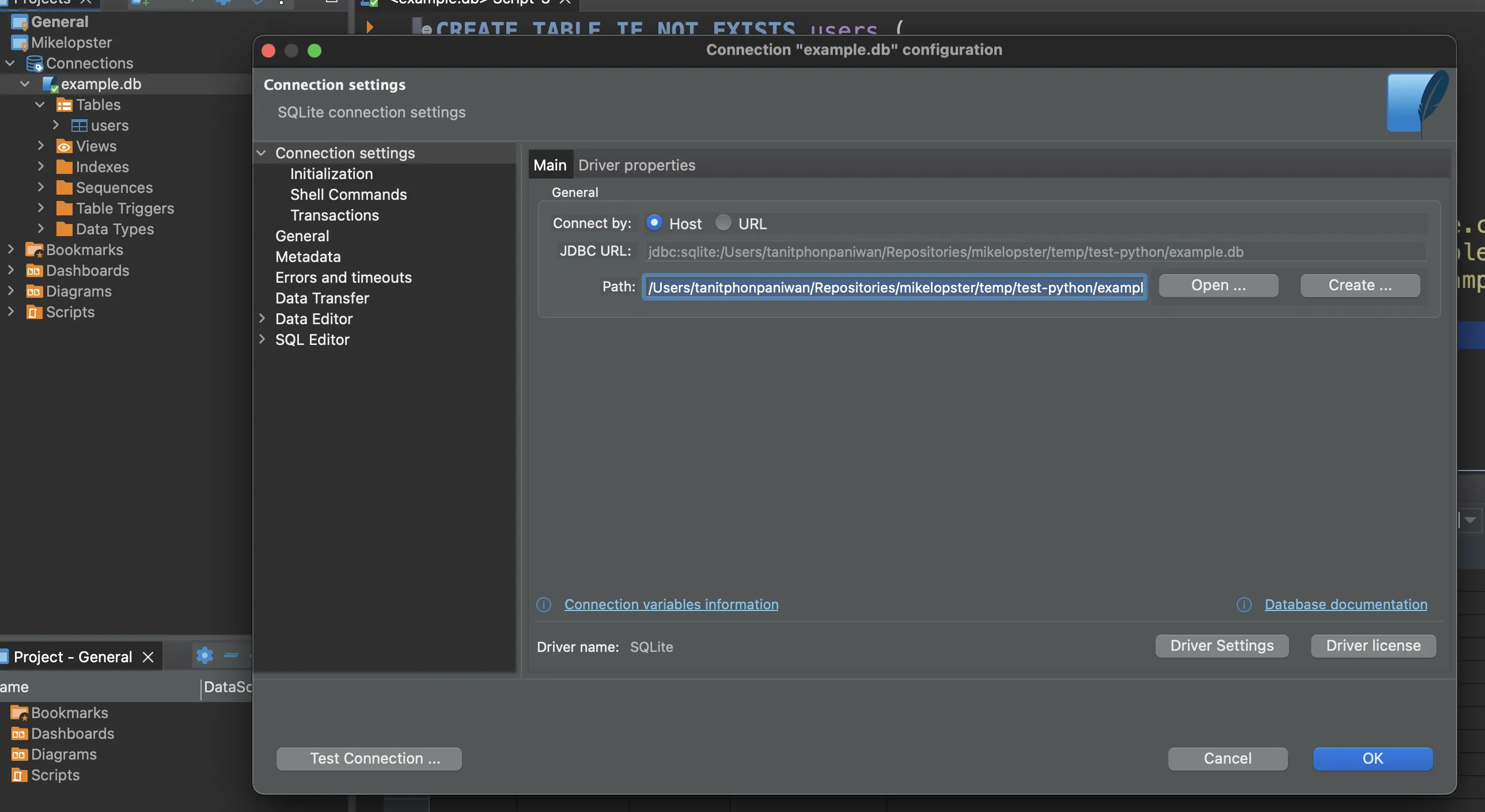
หลังจากนั้น ให้ลองทดสอบการเชื่อมต่อกับ database file นั้นโดยทำการเชื่อมต่อผ่าน program database manager เช่น Dbeaver (https://dbeaver.io/) เข้าไป เพื่อให้มั่นใจก่อนว่าเราสามารถเข้าถึง database ตัวนั้นได้
หลังจากเชื่อมต่อได้เรียบร้อย เราจะลองสร้าง table users ขึ้นมา โดย table users มี fields ดังต่อไปนี้
- name = เก็บชื่อเป็น Text
- age = เก็บอายุเป็นตัวเลข (Integer)
- email = เก็บ email เป็น Text
เราก็จะสามารถสร้างได้จาก SQL ด้านล่างนี้
--- สร้าง table users
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT,
age INTEGER,
email TEXT
)
เมื่อสร้าง database เรียบร้อย ให้ลอง insert ข้อมูลเข้าไปผ่าน SQL
-- insert users
INSERT INTO users (name, age, email) VALUES ('John Doe', 28, '[email protected]');
INSERT INTO users (name, age, email) VALUES ('Jane Smith', 35, '[email protected]');
INSERT INTO users (name, age, email) VALUES ('Emily Davis', 22, '[email protected]');
เมื่อ insert ข้อมูลแล้ว ลองดึงข้อมูลออกมา หากได้ข้อมูลออกมาเรียบร้อยแบบเดียวกับที่ insert = ตอนนี้เรามี table users และข้อมูลอยู่ใน table users แล้วเรียบร้อย
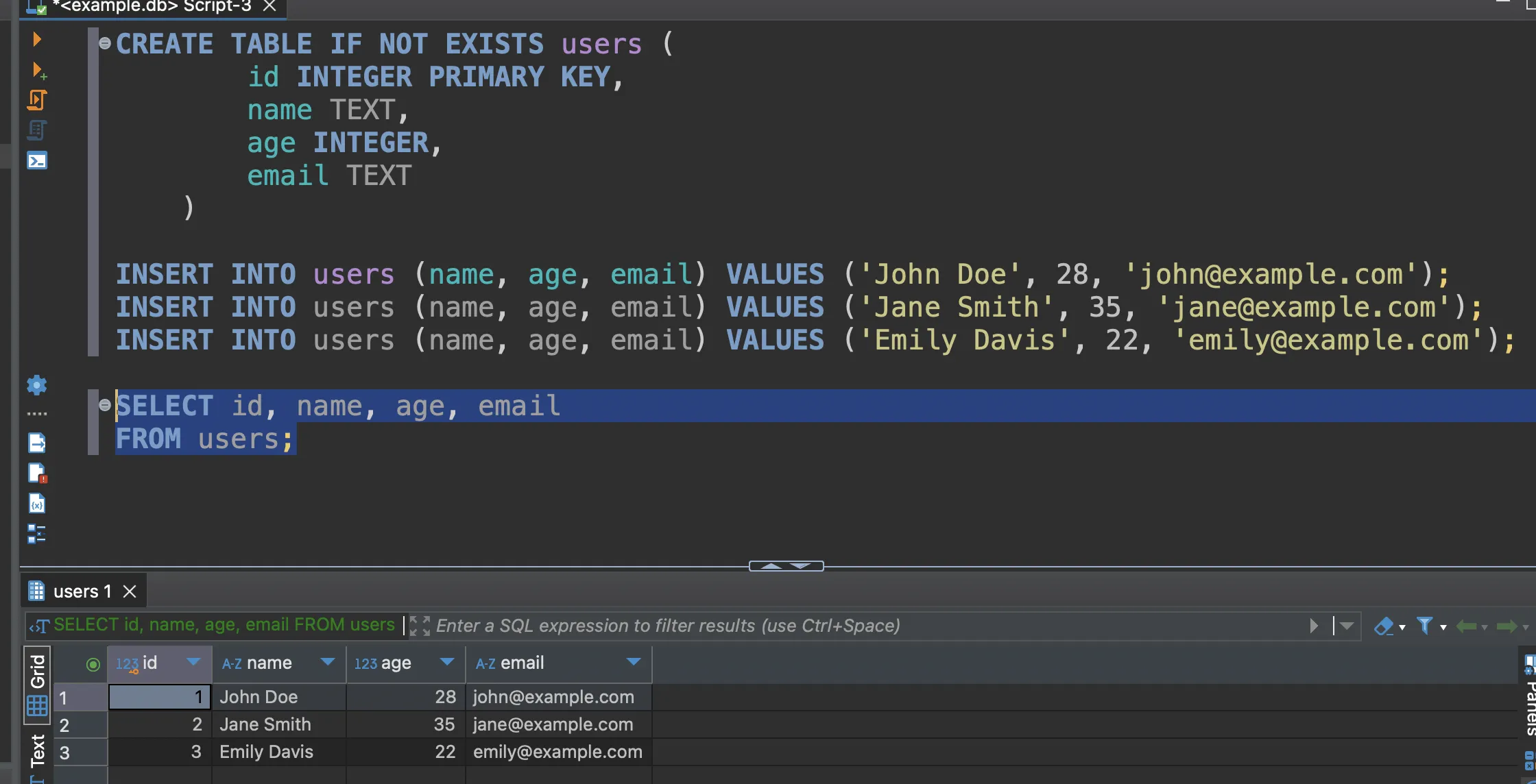
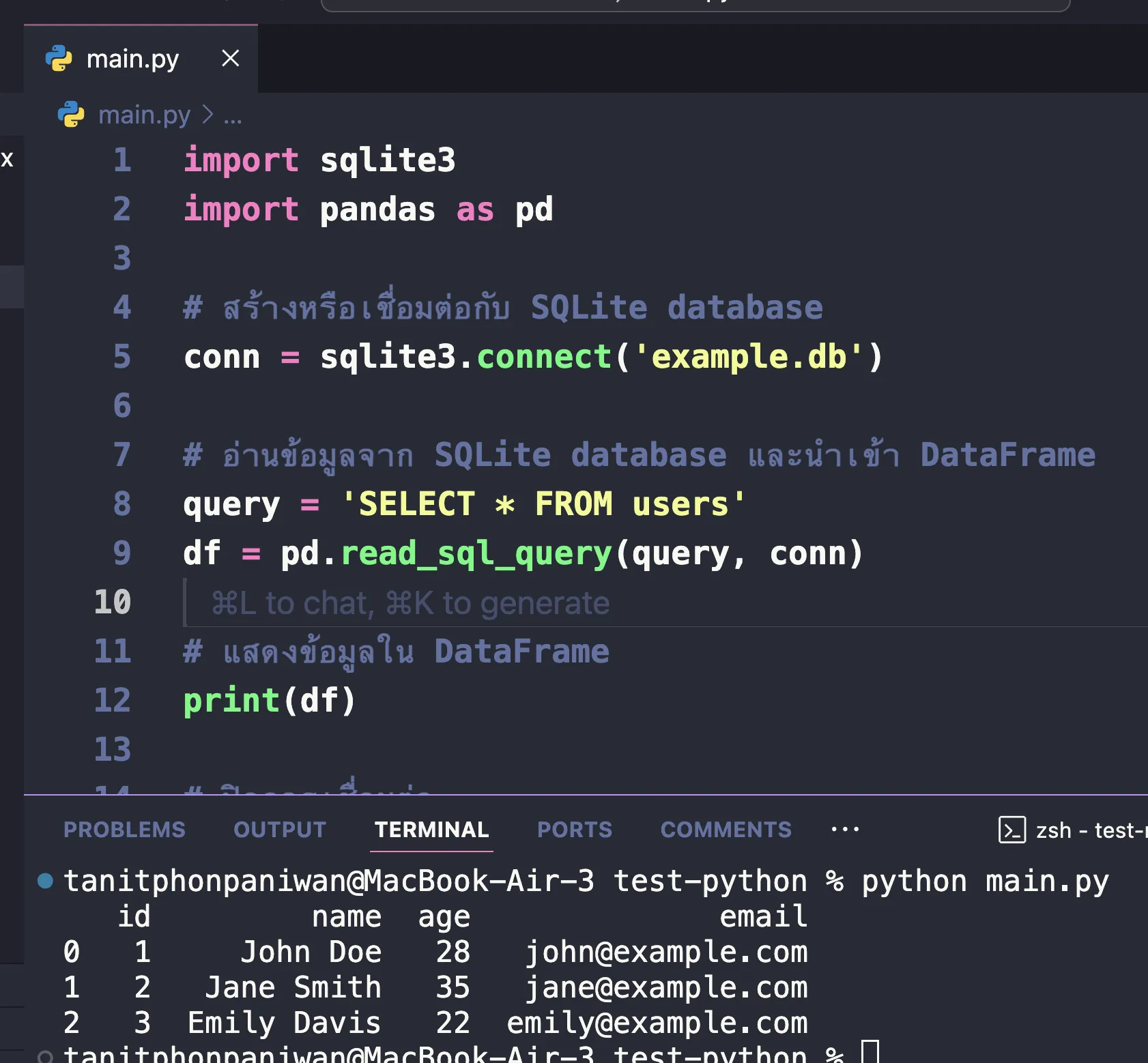
หลังจากนั้น เราก็สามารถใช้ python ผ่าน library pandas ในการอ่านข้อมูลผ่าน SQL เข้ามาได้
import sqlite3
import pandas as pd
# สร้างหรือเชื่อมต่อกับ SQLite database
conn = sqlite3.connect('example.db')
# อ่านข้อมูลจ��าก SQLite database และนำเข้า DataFrame
query = 'SELECT * FROM users'
df = pd.read_sql_query(query, conn)
# แสดงข้อมูลใน DataFrame
print(df)
# ปิดการเชื่อมต่อ
conn.close()
ผลลัพธ์ก็จะได้เป็นลักษณะนี้ออกมา
อย่างที่ทุกคนได้เห็นผ่าน ตัวอย่างของข้อมูลทั้ง 4 ประเภท
เป้าหมายหลักของการใช้ DataFrame ใน pandas คือการจัดการข้อมูลที่มาจากหลายแหล่งที่มา เช่น CSV, Excel, JSON, SQL ฯลฯ ให้อยู่ในรูปแบบโครงสร้างข้อมูลเดียว ซึ่งก็คือ DataFrame นั่นเอง ซึ่งจะช่วยทำให้กระบวนการวิเค�ราะห์ข้อมูลรวดเร็วและสะดวกมากขึ้น
หลังจากที่ข้อมูลถูกอ่านเข้ามาในรูปแบบ DataFrame แล้ว เราจะสามารถใช้ pandas เพื่อทำการประมวลผลหรือวิเคราะห์ข้อมูลได้ทันที เหมือนกับที่เราแนะนำในหัวข้อ pandas ก่อนหน้านี้ได้เลย